对于一部嵌入式设备来说,除了基础功能(通话、短信)外,最重要的可能就是多媒体了。那么一个最简单的问题,什么是多媒体呢? 从字面上来看,这个术语对应的英文单词是“Multi-Media”,直译过来就是多媒体。
简单的说,多媒体是各种形式的媒体(比如文本、音频、视频、图片、动画等等)的组合。
媒体篇将讲解如何在你的应用中增加视频,音频以及图片处理的相关技术。
第一节 基础概念
在讲解如何使用Android提供的API进行录音之前,先介绍一些音频相关的基本概念。
声音(sound)是由物体振动产生的声波。
声音通过介质(空气或固体、液体)传播,然后被人或动物听觉器官所感知,最初发出振动(震动)的物体叫声源。
在计算机领域有两个常用的术语:模拟音频信号和数字音频信号。
- 模拟音频信号(Analog Signal):指自然界中的各种声音,我们通常又把模拟信号称为连续信号,它在一定的时间范围内可以有无限多个不同的取值。
- 数字音频信号(Digital Signal):指保存在计算机中的声音。由于模拟音频信号在一个时间范围内有无限多个取值,所以我们无法把自然界声音无损的保存到计算机中(计算机硬盘的存储容量有限),只能对声音进行采样处理,采样出来的声音只需要达到人耳分辨不出来的水平就可以了。
在电脑上录音的本质就是把自然界中的模拟声音信号转换成计算机所能表示的数字音频信号。
反之,在播放时则是把数字信号还原成模拟音频信号输出。
音频的录制、存储与回放
Multi-Media并不是专门为计算机而生的——只不过后者的出现极大地推动了它的发展。那么和传统的多媒体相比,计算机领域的多媒体系统,会有哪些区别呢?
一个很显然的问题是,我们如何将各种媒体源数字化呢?比如,早期的音频信息是存储在录音带中的,以模拟信号的形式存储。而到了计算机时代,这些音频数据必须通过一定的处理手段才可能存储到设备中,这是我们在数字化时代会遇到的一个常见问题。下面这个图很好地描述了音频从录制到播放的一系列操作流程:
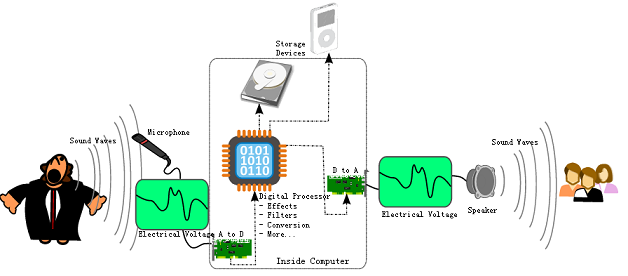
录制过程
首先,音频采集设备(比如Microphone麦克风)捕获声音信息,初始数据是模拟信号。
然后,使用模-数转换器(Analog to Digital Converter)将模拟信号处理成计算机能接受的二进制数据,即数字信号。 随后数据根据需求进行必要的渲染处理,比如音效调整、过滤等等。
此时,处理后的音频数据理论上已经可以存储到计算机设备中了,比如硬盘、USB设备等等。不过由于这时的音频数据体积相对庞大,不利于保存和传输,通常还会对其进行压缩处理。比如我们常见的mp3音乐,实际上就是对原始数据采用相应的压缩算法后得到的。压缩过程根据采样率、位深等因素的不同,最终得到的音频文件可能会有一定程度的失真,
另外,音视频的编解码既可以由纯软件完成,也同样可以借助于专门的硬件芯片来完成。
回放过程
回放过程总体上是录制过程的逆向操作。
首先,从存储设备中取出相关文件,并根据录制过程采用的编码方式进行相应的解码。即将压缩后的数据还原成未压缩之前的状态。
然后,音频系统为这一播放实例选定最终匹配的音频回放设备。
接着,解码后的数据经过音频系统设计的路径传输。
接着,音频数据信号通过数模转换器(Digital to Analog Converter)变换成模拟信号。
最后,模拟信号经过回放设备,还原出原始声音。
第二节 音频采集
声音信号是一种模拟信号,计算机要对它进行处理,必须将它转换为数字声音信号,即用二进制数字的编码形式来表示声音。将模拟信号转换成数字信号,并存放在存储器中的过程,称为数字音频采集。
将模拟音频信号转换为数字音频信号通常要经过:抽样、量化,编码三个步骤。
抽样
抽样也称为采样。由于声音其实是一种能量波,因此也有频率和振幅的特征,频率对应于时间轴线,振幅对应于电平轴线。波是无限光滑的,弦线可以看成由无数点组成,由于存储空间是相对有限的,数字编码过程中,必须对弦线的点进行采样。
采样频率,也称为采样速度或者采样率,定义了每秒从连续信号中提取并组成离散信号的采样个数,它用赫兹(Hz)来表示。采样频率的倒数是采样周期或者叫作采样时间,它是采样之间的时间间隔。通俗的讲采样频率是指计算机每秒钟采集多少个声音样本,是描述声音文件的音质、音调,衡量声卡、声音文件的质量标准。
采样频率必须至少是信号中最大频率分量频率的两倍,否则就不能从信号采样中恢复原始信号。如果信号的带宽是100Hz,那么为了避免混叠现象采样频率必须大于200Hz。人耳能够感觉到的最高频率为20kHz(1kHz = 1000Hz),太高的频率就分辨不出好坏来,因此要满足人耳的听觉要求,则需要至少每秒进行40k次采样,用40kHz表达,这个40kHz就是采样率。
扩展问题:既然20kHz已经分辨不清楚,为什么还有48kHz的采样率?
量化
量化就是把采样得到的样本(模拟量)转换为离散值(数字量)表示。因此量化的过程有时也被称为A/D转换(模数转换)。量化后的样本是用二进制数表示的,二进制数位的多少反映了度量声音波形幅度的精度,称为量化精度。例如,若每个声音样本用16位表示,则声音样本的取值范围是0~65535,精度是1/65536。若每个声音样本用8位表示,则声音样本的取值范围是0~255,精度是1/256。
量化精度越高,声音的质量越好,需要的存储空间也越多。CD标准的量化精度是16Bit,DVD标准的量化精度是24Bit。
编码
根据采样率和量化精度可以得知,相对自然界的信号,音频编码最多只能做到无限接近,至少目前的技术只能这样了,相对自然界的信号,任何数字音频编码方案都是有损的,因为无法完全还原。在计算机应用中,能够达到最高保真水平的就是PCM编码,被广泛用于素材保存及音乐欣赏,CD、DVD以及我们常见的WAV文件中均有应用。因此,PCM约定俗成了无损编码,因为PCM代表了数字音频中最佳的保真水准,并不意味着PCM就能够确保信号绝对保真,PCM也只能做到最大程度的无限接近。我们而习惯性的把MP3列入有损音频编码范畴,是相对PCM编码的。强调编码的相对性的有损和无损,是为了告诉大家,要做到真正的无损是困难的,就像用数字去表达圆周率,不管精度多高,也只是无限接近,而不是真正等于圆周率的值。
经过采样和量化后的声音信号已经是数字形式了,但是为了便于计算机的存储、处理、传输,还必须按照一定的要求进行数据压缩和编码。
为了更形象的解释为什么要对量化后的音乐进行压缩和编码,先介绍两个有关音频编码很重要的术语:比特率和声道。
比特率
比特率是音频文件每秒占据的字节数(比特数),当你在使用比较低的比特率时,你将会丢失声音质量。
比特率规定使用“比特每秒”(bit/s或bps)为单位,ps指的是/s,即每秒。
经常和国际单位制词头关联在一起,如“千”(kbit/s或kbps),“兆”(Mbit/s或Mbps),“吉”(Gbit/s或Gbps) 和“太”(Tbit/s或Tbps)。
CD中的数字音乐比特率为1411.2kbps(也就是记录1秒钟的cd音乐,需要1411.2×1000比特的存储空间)。
声道
一个声道(AudioChannel),简单来讲就代表了一种独立的音频信号,所以双声道理论上就是两种独立音频信号的混合。具体而言,如果我们在录制声音时在不同空间位置放置两套采集设备(或者一套设备多个采集头),就可以录制两个声道的音频数据了。后期对采集到的声音进行回放时,通过与录制时相同数量的外放扬声器来分别播放各声道的音频,就可以尽可能还原出录制现场的真实声音了。
声道的数量发展经历了几个重要阶段,分别是:
- Monaural(单声道)
- 早期的音频录制是单声道的,它只记录一种音源,所以在处理上相对简单。播放时理论上也只要一个扬声器就可以了——即便有多个扬声器,它们的信号源也是一样的,起不到很好的效果
- Stereophonic(立体声)
- 之所以称为立体声,是因为人们可以感受到声音所产生的空间感:大自然中的声音就是立体的,比如办公室里键盘敲击声,马路上汽车鸣笛,人们的说话声等等。
那么这些声音为什么会产生立体感呢?
我们知道,当音源发声后(比如你右前方有人在讲话),音频信号将分别先后到达人类的双耳。在这个场景中,是先传递到右耳然后左耳,并且右边的声音比左边稍强。这种细微的差别通过大脑处理后,我们就可以判断出声源的方位了。
这个原理现在被应用到了多种场合。在音乐会的录制现场,如果我们只使用单声道采集,那么后期回放时所有的音乐器材都会从一个点出来;反之,如果能把现场各方位的声音单独记录下来,并在播放时模拟当时的场景,那么就可以营造出音乐会的逼真氛围。
最基本的立体声是两声道:左声道、右声道。还有更多声道的立体声,也即环绕声,其中包括主要的左右声道,还有环绕的副声道左右,中置,单独低音等5-7个声道。
为什么要压缩?
要算一个PCM音频流的码率是一件很轻松的事情,公式为:采样率×采样大小(即量化精度)×声道数。
如一个采样率为44.1KHz,采样大小为16bit,双声道的PCM编码的WAV文件,它的数据速率则为:1
44.1K × 16 × 2 = 1411.2Kbps
然后再将码率除以8,就可以得到这个WAV的数据速率,即176.4KB/s。
这表示存储一秒钟采样率为44.1KHz,采样大小为16bit,双声道的PCM编码的音频信号,需要176.4KB的空间,1分钟则约为10.34M。
显然,这对大部分用户是不可接受的,尤其是喜欢在电脑上听音乐的朋友,要降低磁盘占用,只有两种方法:
- 降低采样指标。
- 压缩。
降低指标是不可取的,因此专家们研发了各种压缩方案。
由于用途和针对的目标市场不一样,各种音频压缩编码所达到的音质和压缩比都不一样。有一点是可以肯定的,它们都压缩过。
第三节 开始录音
在Android中有两种方法可以实现录音功能,使用MediaRecorder类和AudioRecorder类:
- MediaRecorder类十分简单好用,但是灵活性不足。
- AudioRecorder提供了更多的自由度,但是使用稍微会有点复杂,它们各自有对应的应用场景。
具体区别:
首先,录音时输出的数据不同。
- MediaRecorder录制出来的是一个音频文件。该文件是经过压缩后的,即在录音之前需要为其设置编码方式等一系列参数,设置完毕后MediaRecorder类会依据参数值自动完成声音的收集、编码、压缩等步骤。
- AudioRecorder直接捕获到的是未经过任何处理的原始音频流,开发者可以实时随意处理音频流。
然后,对声音操作的自由度不同。
- MediaRecorder将录音的所有步骤都封装起来,只会输出一个声音文件。
- AudioRecorder可以实现边录边播(实现即时聊天功能)以及对音频的实时处理,如降噪,合成(如“会说话的汤姆猫”)。
- 优点:语音的实时处理,可以用代码实现各种音频的封装。
- 缺点:输出是PCM语音数据,如果保存成音频文件,是不能够直接播放的,必须另写代码对PCM数据编码和压缩。
MediaRecorder
使用MediaRecorder类从设备捕捉音频的大体步骤:
1、创建一个新实例android.media.MediaRecorder。
2、使用MediaRecorder.setAudioSource()设置音频源。
3、使用MediaRecorder.setOutputFormat()设置输出文件格式。
4、使用MediaRecorder.setOutputFile()设置输出文件名。
5、使用MediaRecorder.setAudioEncoder()设置音频编码器。
6、在MediaRecorder实例上调用MediaRecorder.prepare()。
7、调用MediaRecorder.start()开始音频捕捉。
8、调用MediaRecorder.stop()停止音频捕捉。
9、录音完毕后调用MediaRecorder.release()方法释放资源。
MediaRecorder类的具体用法请参考 Audio Capture 。
音频源:
音频源指从何处录制声音,通常会选择电话的“麦克风”。 使用MediaRecorder.AudioSource类来表示可选的所有音频源。
范例1:MediaRecorder.AudioSource类。1
2
3
4
5
6MediaRecorder.AudioSource.MIC 麦克风,即手机话筒
MediaRecorder.AudioSource.DEFAULT 默认情况下通常代表MIC
MediaRecorder.AudioSource.VOICE_CALL Voice call uplink and downlink source
MediaRecorder.AudioSource.VOICE_DOWNLINK Voice call downlink source
MediaRecorder.AudioSource.VOICE_UPLINK Voice call uplink source
MediaRecorder.AudioSource.VOICE_RECOGNITION Usually DEFAULT source
文件格式与音频编码:
首先我们要知道的是,每个音频文件都有两部分:文件格式(也叫音频容器),数据格式(也叫音频编码)。
文件格式描述了这个文件它自己的格式,而它里面的实际音频数据能使用很多不同的方式编码。例如,一个后缀为caf的文件是一种文件格式,它能够包含用MP3、线性pcm等其他许多格式编码的音频数据。
换句话说,文件格式就像是桶一样,里面可以装很多水,那些水就是那些音频数据。桶有很多种外形,也就是有很多种文件格式,而且不一样的桶,也需要装不同的水(石油桶用来装石油)。caf这种桶就可以装各种各样的水,不过有些桶就只能装几种类型的水。
使用MediaRecorder类的setOutputFormat()方法可以设置录音时,输出的音频文件的格式。MediaRecorder.OutputFormat类来表示可选的音频文件格式。
范例2:MediaRecorder.OutputFormat类。1
2
3
4
5
6
7MediaRecorder.OutputFormat.AMR_NB API Level 10
MediaRecorder.OutputFormat.AMR_WB API Level 10
MediaRecorder.OutputFormat.DEFAULT API Level 1
MediaRecorder.OutputFormat.MPEG_4 API Level 1
MediaRecorder.OutputFormat.RAW_AMR API Level 3
MediaRecorder.OutputFormat.THREE_GPP API Level 1
MediaRecorder.OutputFormat.AAC_ADTS API Level 16
AMR
AMR(Adaptive multi-Rate简称自适应多速率音频编码) 它即是一种音频编码格式也是一种文件格式。
AMR编码压缩比非常高,但是音质比较差,主要用于语音类的音频压缩,效果还是很不错的,不适合对音质要求较高的音乐、歌曲类音频的压缩。
现在很多智能手机都支持多媒体功能,特别是音频和视频播放功能,而AMR文件格式是手机端普遍支持的音频文件格式。
AMR文件就是存储AMR语音编码的音频文件。
很多手机允许你存储短时间的AMR格式录音,在开源和商业软件有和其他格式转换的程序,例如MP3,但是要记住AMR并不是理想的记录声音的方式。AMR文件扩展名是.amr。
AMR被标准语音编码3GPP在1998年10月选用,现在广泛在GSM和UMTS中使用。它使用1-8个不同的位速编码。
AMR又称为AMR-NB,即窄带自适应多速率,还有另一种AMR-WB宽带自适应多速率。
RAW_AMR
此常量与AMR_NB等价。在API Level 16中已经不推荐使用,改用AMR_NB代替。
THREE_GPP
即.3gp格式的文件,通常是以视频文件的形式展现。
3GP是一种多媒体储存格式,由Third Generation Partnership Project(3GPP)定义的,MPEG-4 Part 14(MP4)的一种简化版本,减少了储存空间和较低的带宽需求,主要用于3G手机上,让手机上有限的储存空间可以使用。
3GP档案影像的部份可以用MPEG-4 Part 2、H.263或MPEG-4 Part 10 (AVC/H.264)等格式来储存,声音的部份则支援AMR-NB、AMR-WB、AMR-WB+、AAC-LC或HE-AAC来当作声音的编码。目前3GP档案有两种不同的标准:
- 3GPP(针对GSM手机,副档名为.3gp)
- 3GPP2(针对CDMA手机,副档名为.3g2)
这两种格式影像方面都采用MPEG-4及H.263,而声音则采用AAC或AMR标准。
3GP格式视频有两种分辨率:
1、分辨率176×144,适合市面上所有支持3GP格式的手机。
2、分辨率320×240,清晰,适合高档手机、MP4播放器、PSP以及苹果iPod.
AAC
AAC(Advanced Audio Coding简称高级音频编码)基于MPEG-2的音频编码技术。目的是取代MP3格式。
2000年,MPEG-4标准出现后,AAC重新集成了其特性,加入了SBR技术和PS技术,为了区别于传统的MPEG-2 AAC又称为MPEG-4 AAC。
作为一种高压缩比的音频压缩算法,AAC压缩比通常为18:1,也有数据说为20:1,远胜mp3;在音质方面,由于采用多声道,和使用低复杂性的描述方式,使其比几乎所有的传统编码方式在同规格的情况下更胜一筹。
但是AAC在Android的API Level 16以后才支持的。
注:视频文件也同样区分文件格式和编码格式
使用MediaRecorder类的setAudioEncoder()方法可以设置录音时所要使用的音频编码格式。
范例3:MediaRecorder.AudioEncoder类。1
2
3
4
5
6MediaRecorder.AudioEncoder.AAC API Level 10
MediaRecorder.AudioEncoder.AAC_ELD API Level 16
MediaRecorder.AudioEncoder.AMR_NB API Level 1
MediaRecorder.AudioEncoder.AMR_WB API Level 10
MediaRecorder.AudioEncoder.DEFAULT API Level 1
MediaRecorder.AudioEncoder.HE_ACC API Level 16
AudioRecord
刚刚介绍了如何使用MediaRecorder类来进行录音,该类十分容易使用并且可以简单快速的进行录音,同时也可以将音频压缩存储为mpeg4或者3gpp格式的。但是如果你需要原始数据,做一些音频处理,则就无法使用MediaRecorder类来完成了。AudioRecord类则可以输出未压缩的原始音频流,你可以将音频流写入到一个文件,保存为wav格式等。
使用AudioRecord类记录音频的步骤如下:
1、创建一个android.media.AudioRecord类的实例。
2、使用AudioRecord.startRecording()方法开始录音。
3、使用AudioRecord.read()方法读取录到的原始音频流。
4、使用AudioRecord.stop()方法停止录音。
范例1:AudioRecord类构造方法。1
2
3
4
5
6
7
8
9
10// 第一个参数:指定音频源,取值可以是MediaRecorder.AudioSource类定义的常量。
// 第二个参数:设置采样率,单位Hz,44100Hz是唯一可以在所有设备上正常工作的。
// 但是也有其他采样率如22050,16000和11025可以在某些设备上工作。
// 第三个参数:设置声道数。取值为:AudioFormat.CHANNEL_IN_MONO 和 AudioFormat.CHANNEL_IN_STEREO。
// 前者通常可以在所有设备上正常工作。
// 第四个参数:设置音频的编码格式。取值为:AudioFormat.ENCODING_PCM_16BIT 和 AudioFormat.ENCODING_PCM_8BIT。
// 第五个参数:设置录音时,用于保存录出来的音频数据的buffer大小。
// 如果你不知道如何设置缓冲区大小,则可以调用getMinBufferSize(int, int, int)方法来计算。
// 该方法中的三个参数的含义和此构造方法的参数完全相同。
public AudioRecord(int audioSource,int sampleRateInHz,int channelConfig,int audioFormat,int bufferSizeInBytes)
本节参考阅读:
- www.androiddevblog.net(链接已失效)
- http://developer.android.com/intl/zh-CN/reference/android/media/AudioRecord.html