第一节 基础常识
在日常开发中,我们经常接触到的图像一般分为“位图”和“矢量图”两大类。
不过在开始介绍它们之前,我们先来思考一个问题:现实中的图像是如何被存储到电脑中的?
图像的数字化
我们都知道在计算机的世界里只有0和1,因此如果要在计算机中处理图像,必须先把现实世界里的东西(照片、图纸等)转变成计算机能够接受格式,然后才能进行处理。
转化图像主要有三个步骤:采样、量化与压缩编码。
采样
采样阶段,主要是把一副现实世界的图像,在水平和垂直方向上等间距地分割成矩形网格,每个网格记录不同的颜色,最终一副现实中图像就被采样成有限个网格构成的集合。
如下图所示,左图是要采样的物体,右图是采样后的图像。
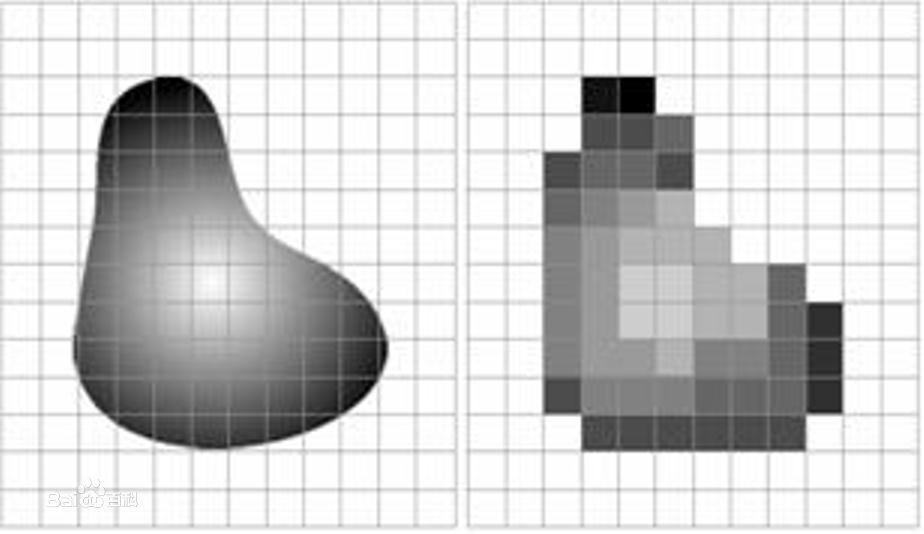
从上图可以看出来,网格的数量越多,图片的还原度就越高,看起来也就越真实。
量化
量化阶段,主要是确定图像里的每个网格,应该占多少字节。
具体来说,计算机会为图像选择合适的 “色彩模型” 和 “色彩空间” ,确定了这两者也就确定了每个网格该占多少字节。
色彩模型(Color Model)是一种抽象数学模型,通过一组数值来描述颜色。常见的模型有:
- RGB模型:规定红、绿、蓝 3 个分量描述一个颜色。
- CMYK模型(主要在印刷行业使用):规定青色(Cyan)、品红色(Magenta)、黄色(Yellow)、黑色(Black)4个分量描述一个颜色。
色彩空间(Color Space)是色彩模型的具体细化:
我们虽然知道,RGB模型用规定红、绿、蓝 3 个分量描述颜色,然而并没有确定红色、绿色、蓝色到底是什么。
比如你知道 (255,0,0)是红色,但是并不知道这个红用的色值是多少,更不知道从 0-255 每一级红色差了多少。
而色彩空间要有确切的定义,比如使用 RGB 色彩模型的 sRGB 色彩空间最大红色的定义就是CIE XYZ: 0.4360657, 0.2224884, 0.013916。
也就是说,RGB色彩模型下面会有多个色彩空间,它们对颜色有各自的定义。
常见的色彩空间有:AdobeRGB、sRGB等,其中sRGB能表示的颜色数量要比AdobeRGB少。
资料 - 维基百科:
RGB色彩空间根据实际使用装置系统能力的不同,有各种不同的实现方法。截至2006年,最常用的是24位实现方法,也就是红绿蓝每个通道有8位元或者256色级。基于这样的24位RGB模型的色彩空间可以表现256×256×256 ≈ 1677万色。
压缩
图像量化完毕之后,我们就得到了一个数字化的图像了,但是图像的体积会非常大,不利于存储和传输,所以还需要对图像进行编码压缩。
图像数据之所以能被压缩,就是因为数据中存在着冗余。像数据的冗余主要表现为:
图像中相邻像素间的相关性引起的空间冗余;
图像序列中不同帧之间存在相关性引起的时间冗余;
不同彩色平面或频谱带的相关性引起的频谱冗余。
图像压缩分为 有损数据压缩 和 无损数据压缩 两种,后者不会让图片失真。
无损图像压缩
比如说,如果一张图像里只有蓝天,那么我们只需要记录蓝天的起始点和终结点就可以了,但是事实不会这么简单,因为蓝色可能还会有不同的深浅,天空有时也可能被树木、山峰等对象掩盖,这些就需要另外记录。
从本质上看,无损压缩就是通过删除一些重复数据,来减少图像在磁盘上的体积。因而他可以完全恢复原始数据而不引起任何失真,但压缩率比较低。
有损图像压缩
有损压缩图像的特点是保持颜色的逐渐变化,删除图像中颜色的突然变化。
生物学中的大量实验证明,人类大脑会使用最接近的颜色来填补所丢失的颜色,简称脑补。例如,对于蓝色天空背景上的一朵白云,有损压缩的方法就是删除图像中景物边缘的某些颜色部分。当在屏幕上看这幅图时,人类的大脑会利用在景物上看到的颜色填补所丢失的颜色部分。从本质上看,有损压缩是利用了人眼对图像中某些成分不敏感的特性来实现的。允许压缩过程中损失一定的信息;虽然展示的时候不能完全恢复原始数据,但是所损失的部分对理解原始图像的影响缩小,却换来了大得多的压缩比。
位图
位图图像(bitmap),亦称为点阵图像或栅格图像,是一个M行N列的点组成的一个矩阵,矩阵每个元素都是一个网格,每个网格都用来表示一个颜色,这个网格被称为像素点。
对于位图来说,它常见的颜色模型有:RGB、CMYK。
特点:一张位图中的每个像素点所能表示的颜色越多,整张位图的色彩就越丰富。像素点所能显示的颜色的数量被称为位深。
根据位深度,可将位图分为1、4、8、16、24及32位图像等规格。
比如位深为1的位图,它里面的每个像素点只能表示2^1个颜色,即只能表示黑白两色,其它以此类推。
- 我们知道任何颜色可以由R、G、B三基色混合而成,因此如果一个位图的位深是16的话,那么通常会让R占5位、G占6位、B占5位,因为效果好。Android中位图每个像素点的RGB占多少位是有规定的,常见的取值有:ALPHA_8、ARGB_4444(A表示透明度)、ARGB_8888、RGB_565。
- 位图的尺寸(分辨率)越大,其所包含的像素点就越多,图就越细腻、清晰,相应的图片的体积就越大。
位图常见文件格式
| 文件类型 | 后缀名 | 透明通道 | 特点 |
|---|---|---|---|
| JPEG | .jpg 或 .jpeg | 不支持 | 有损压缩,体积小,应用广泛 |
| PNG-8 | .png | 索引透明:完全透明或全不透明 Alpha透明:带过渡的透明 |
无损压缩。 像素点保存的不是颜色信息,而是从图像中挑选出来的具有代表性的颜色编号,每一编号对应一种颜色。 一张图最多支持256个编号。 |
| PNG-24 | .png | 不支持 | 无损压缩,体积比png8大 |
| PNG-32 | .png | 支持0~255级透明度 | 无损压缩,体积比png24大 |
矢量图
矢量图形是用点、直线或者多边形等几何图元表示的图像。矢量图形与使用像素表示图像的位图不同,它只会保存图形的相关信息。
假设现在有一张图像,它里面只有一个圆形,如果用位图存储的话,就需要记录圆形的尺寸以及图像里每个像素点的信息。
如果要用矢量图的话,我们就只保存圆的半径r、圆心坐标、轮廓样式与颜色、填充样式与颜色等几个信息在图片文件中就好了,当需要显示图片时,就用程序把文件加载到内存,然后解析各个参数,最后执行绘制操作。
矢量图的特点
1、矢量图文件的体积与分辨率和图像大小无关,只与图像的复杂程度有关。
2、矢量图可以无限缩放,对它进行缩放,旋转或变形操作时,图形不会产生锯齿效果,边缘会非常顺滑。
3、矢量图难以表现色彩层次丰富的逼真图像效果,因为颜色丰富的图可能每个点的颜色都不一样,这种场景下位图比矢量图更适合。
4、矢量图只能靠软件生成。
重要提示1:图片在内存中的体积=分辨率*每个像素点的位深,与磁盘上占用的空间无关。
重要提示2:矢量图只是让图片在磁盘上的体积降低了,它被加载到内存后的体积与位图是一样的。
SVG图片
SVG全称是Scalable Vector Graphics(可缩放矢量图形),它是一种被广泛应用的矢量图,我们Android研发也经常能接触到,下面来创建一个SVG图片体验一下。
范例1:画一个红色的矩形。1
2
3<svg width="48" height="48" version="1.1" xmlns="http://www.w3.org/2000/svg">
<rect x="0" y="0" width="48" height="48" fill="#FF0000"/>
</svg>
语句解释:
- SVG图片的内容使用XML文件来记录,且必须用svg标签做为根节点。
- 目前各大浏览器都支持svg文件,所以直接拖当浏览器中就可以查看效果。
提示:大家可以去 W3C 和 mozilla 中学习SVG的基础语法,笔者就不冗述了。
本节参考阅读:
- 维基百科 - 色彩空间
- 百度百科 - CMYK
- 百度百科 - 图像数字化
- 知乎 - 色彩空间与色彩模型的本质区别是什么?
- 百度百科 - PNG
- 维基百科 - 矢量图
- 维基百科 - 位图
- 百度百科 - 矢量图
第二节 Android中的图片处理
进程的内存限制
移动设备通常都只有有限的系统资源,Android设备是允许多个同时进程存在的,为了保证手机内存不被某个进程独占,系统会为每个进程设置“最小内存”和“最大内存”。
最小内存限制
不同的Android版本,虚拟机所分配的内存大小是不同的,在各个版本的《Android兼容性定义文档》的3.7章节中,给出了不同尺寸和密度的手机屏幕下应用程序所需的最小内存。如:
Android2.2中,对于中等或者低密度的屏幕尺寸,虚拟机必须为每个应用程序分配至少16MB的内存。
Android8.1中,内存分配的情况如下图所示。
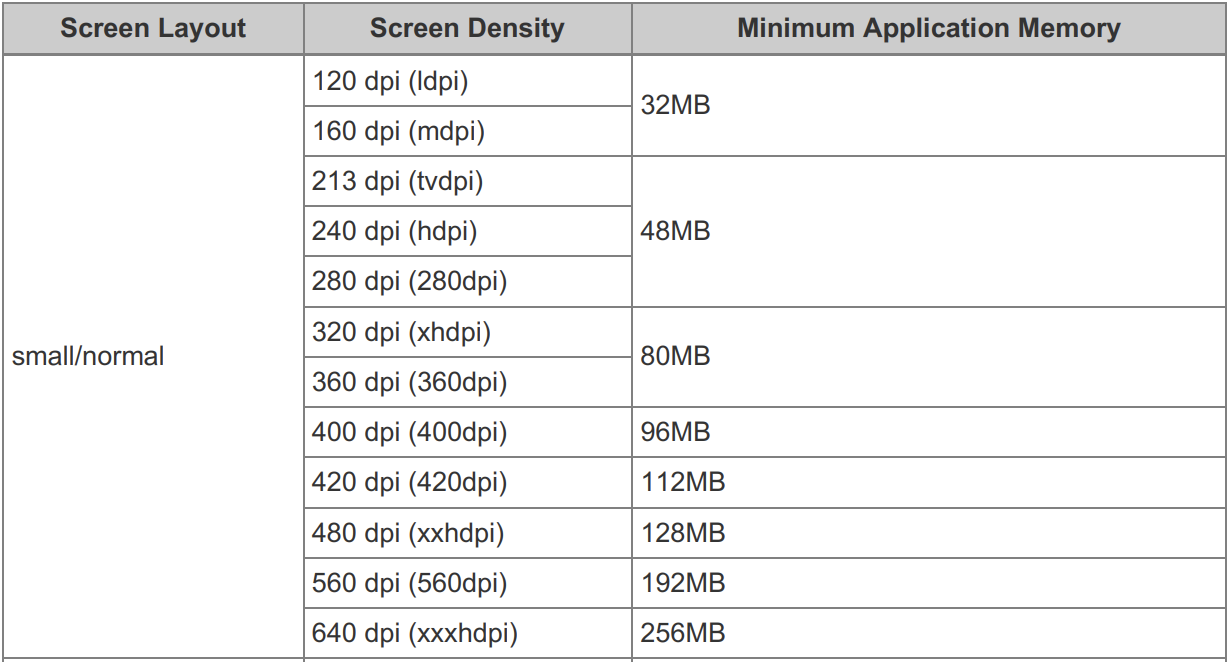
注意:上述的内存值被认为是最小值,在很多设备中可能会为每个应用程序分配更多的内存。
最大内存限制
如果你想知道设备的单个进程最大内存的限制是多少,并根据这个值来估算自己应用的缓存大小应该限制在什么样一个水平,你可以使用ActivityManager#getMemoryClass()来获得一个单位为MB的整数值,一般来说最低不少于16MB,对于现在的设备而言这个值会越来越大,32MB,128MB甚至更大。
- 需要知道的是,就算设备的单进程最大允许是128M,操作系统也不会在进程刚启动就给它128M,而是随着进程不断的有需求是才不断的分配,直到进程达到阀值(128M),系统就会抛出OOM。
图片的加载
图像会有各种各样的尺寸,在很多情况下,图片的实际尺寸往往会比UI界面的显示尺寸更大。例如,使用Android设备的摄像头拍摄的照片,照片的分辨率往往要远高于设备的屏幕分辨率。
考虑到手机内存有限,在需要显示图片时理想的做法是,程序会先将大分辨率的图片缩小到与UI组件相同的尺寸后,再将它加载到内存中来。因为一张比UI组件尺寸大的高分辨率的图片并不能带给你任何可见的好处,却要占据着宝贵的内存,以及间接导致由于动态缩放引起额外的性能开销。
范例1:使用BitmapFactory所提供的如下几个方法,可以将图片加载到内存中。1
2
3public static Bitmap decodeFile(String pathName, BitmapFactory.Options ops);
public static Bitmap decodeResource(Resources res, int id, BitmapFactory.Options ops);
public static Bitmap decodeByteArray(byte[] data, int offset, int length, BitmapFactory.Options ops);
语句解释:
- 使用这些方法加载图片的时候,若设置BitmapFactory.Options类的inJustDecodeBounds属性为true,则BitmapFactory不会加载图片的真正数据,即这些方法的返回值对象为null。
- 但是却会将图片的实际宽度、高度、类型设置到outWidth,outHeight和outMimeType属性中。
- 这项技术允许你在创建Bitmap(并分配内存)之前读取图片的尺寸和类型。
范例2:加载图片尺寸。1
2
3
4
5
6
7
8
9
10
11
12
13public void loadSize(){
BitmapFactory.Options options = new BitmapFactory.Options();
// options.inJustDecodeBounds标识是否仅获取图片的尺寸信息。
// 若值为true则BitmapFactory不会加载图片,只是获取图片的尺寸信息。
options.inJustDecodeBounds = true;
BitmapFactory.decodeResource(getResources(), R.id.myimage, options);
// 当inJustDecodeBounds为true且图片的尺寸加载完毕后,图片的高度会保存在options.outHeight中。
int imageHeight = options.outHeight;
// 图片的宽度会保存在options.outWidth中。
int imageWidth = options.outWidth;
}
现在图片的尺寸已经知道了,为了告诉解码器如何对图像进行采样,加载更小版本的图片,需要为BitmapFactory.Options对象中的inSampleSize属性设置值。
- inSampleSize表示图片的缩放倍数。
- 若inSampleSize > 1则执行缩小操作,返回的图片是原来 1/inSampleSize 。
- 若inSampleSize <= 1则结果与1相同。
例如一张分辨率为2048*1536px的图像,假设Bitmap配置为ARGB_8888,整张图片加载的话需要12M。
- 2024*1536个像素点 * 每个像素点使用4字节表示 /1024/1024 = 12MB
- ARGB4_8888,即每个像素中A、R、G、B的色值各使用1字节(0~255)来表示。
若使用inSampleSize值为4的设置来解码,产生的Bitmap大小约为512*384px,相较于完整图片占用12M的内存,这种方式只需0.75M内存。
范例3:完整范例。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
ImageView img = (ImageView) findViewById(R.id.img);
Bitmap bm = decodeSampledBitmapFromResource(getResources(),R.drawable. img,200,200);
img.setImageBitmap(bm);
}
public static Bitmap decodeSampledBitmapFromResource(Resources res, int resId, int reqWidth, int reqHeight){
final BitmapFactory.Options options = new BitmapFactory.Options();
options.inJustDecodeBounds = true;
BitmapFactory.decodeResource(res, resId, options);
options.inSampleSize = calculateInSampleSize(options, reqWidth, reqHeight);
options.inJustDecodeBounds = false;
return BitmapFactory.decodeResource(res, resId, options);
}
public static int calculateInSampleSize(BitmapFactory.Options options, int reqWidth, int reqHeight) {
// Raw height and width of image
final int height = options.outHeight;
final int width = options.outWidth;
int inSampleSize = 1;
if (height > reqHeight || width > reqWidth) {
if (width > height) {
inSampleSize = Math.round((float) height / (float) reqHeight);
} else {
inSampleSize = Math.round((float) width / (float) reqWidth);
}
}
return inSampleSize;
}
}
语句解释:
- 值得注意的是,ImageView在默认情况下会自动帮助我们缩放图片,从而使该图片的内容可以全部显示在ImageView中。
- 但是它仅仅是将显示的内容缩放了,却并不会将图片的容量也给缩小。
- 换句话说ImageView的缩放是在图片加载入内存之后进行的,而本范例则是在图片加载之前执行的。
- 使用2的次幂来设置inSampleSize值可以使解码器执行地更加迅速、更加高效。
本节参考阅读:
图片的缓存
不论是Android还是iOS设备,流量对用户来说都是一种宝贵的资源,所以开发时都尽可能的少消耗用户的流量,为此就需要对网络上的图片进行缓存。
目前比较常见的图片缓存策略是三级缓存:
- 首先,由于将图片从磁盘读到内存也是需要时间的,所以我们会把一些频繁被使用到的图片缓存再内存中,这样能进一步减少图片加载的时间。
- 此乃第一级缓存,使用LruCache类实现。
- 然后,由于内存的大小是有限制的,所以不能在内存中缓存太多图片,当内存缓存达到一定值时,就需要将一些图片从一级缓存中删除。并把这些被删除的图片放入到软引用中,这样既能缓存又不阻止内存回收。
- 此乃第二级缓存,使用LinkedHashMap类实现。
- 最后,当需要显示一张图片时,我们会从服务其端下载它,完成后将它保存到本地,以后就不用重新下载了。
- 此乃第三级缓存,使用DiskLruCache类实现。
当需要加载图片时,会执行如下步骤:
- 首先,从一级缓存中查看,若找到了则直接显示,若没找到则查看二级缓存。
- 然后,若在二级缓存中找到了,则直接显示,并将该图片从二级缓存移动到一级缓存中。
- 接着,若在二级缓存中也没找到,则去三级缓存中找(本地磁盘),若没找到则去服务器端下载,下载完后缓存到本地。
- 最后,若在三级缓存中找到了,则将图片读取内存显示,并放入到一级缓存中。
LruCache
我们来看一下,实现第一级缓存所需要使用的LruCache类。
LruCache是Android3.1中所提供的一个工具类,通过support-v4兼容包也可以使用它。
LruCache的特点有:
- 第一,实现原理基于LRU算法,这种算法的核心思想为:当缓存快满时,会将近期最少使用的数据从缓存中删除。
- 第二,它内部采用LinkedHashMap以强引用的方式存储数据。
LruCache的使用也很简单,这里给出一个范例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 下面这个LruCache中保存的数据,key是String类型的,value是Integer类型的。
// 构造方法里的数字3,表示当前LruCache的缓存容量是3。
LruCache<String, Integer> lruCache = new LruCache<String, Integer>(3) {
// 当需要计算某个数据所占据的大小时,此方法被调用。
protected int sizeOf(String key, Integer value) {
// 这里总是返回1,也就意味着当前LruCache中最多只能保存3个数字。
return 1;
}
};
// 向缓存中添加数据。
lruCache.put("1", 100);
lruCache.put("2", 200);
lruCache.put("3", 300);
// 调用get方法从lruCache中读取数据,由于没存储过4,所以会输出:null。
System.out.println(lruCache.get("4"));
// System.out.println(lruCache.get("1"));
// 由于咱们这个lruCache只能保存3个数据,所以当保存第四个数的时候,就会把数字1给踢出。
lruCache.put("4", 400);
// 由于数字1被踢出了,所以此处会输出:null。
System.out.println(lruCache.get("1"));
}
}
语句解释:
- 上面之所以会踢出1,是因为在1、2、3三个数字中,1最久没被使用过。
- 如果把上面第23行代码给解除注释,则当4被加入到缓存中时,被踢出的将是2。
- LruCache类还有一些有用的方法:evictAll(清空数据)、size(当前容量)、remove(删除)等等。
LruCache虽然简单,但是我们不能满足于只会用它,还应该知道它的内部原理。
LruCache内部是通过LinkedHashMap类来实现的,既然说到了LinkedHashMap,下面就来介绍一下HashMap类。
HashMap
在Map接口的众多子类中,比较常用的是HashMap类,在它的内部是使用数组来存储每一个元素的,虽然是基于数组实现,但它却可以高速存取元素。
- 原因就是HashMap的内部在查找元素的时候,并不是从数组头部依次遍历匹配。
- 而是依据key的hashCode值来计算出一个下标,查找时会从这个下标开始依次查找。
范例1:HashMap的get方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value);
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
// No entry for (non-null) key is present; create one
modCount++;
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
addNewEntry(key, value, hash, index);
return null;
}
语句解释:
- 在此方法中若参数key不为null,则会先计算key的hashCode码,然后从对应的位置开始依次遍历余下的元素。
问:对象的hashCode码不是唯一的吗? 为什么在得到hashCode码还会存在“依次遍历余下的元素”这个操作呢?
答:hashCode码并不是唯一的,比如下面的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
HashMap<A, Integer> hashMap = new HashMap<A, Integer>();
hashMap.put(new A(), 5);
hashMap.put(new A(), 6);
System.out.println(hashMap.size()); // 输出2。
}
class A {
public int hashCode() {
return 1;
}
}
}
语句解释:
- 也就是说,两个完全不同的对象,它们的hashCode码却可能相同。
查找算法
笔者在此简单的普及一下数据结构中的“查找”算法的基本概念(没错,纯粹是为了装逼!)。
有n条记录的集合T是实施查找的数据基础,T称为“查找表”(Search Table)。
- 比如在集合{1,2,3}中查找出数字2,则“集合{1,2,3}”被称为查找表。
常见的查找算法有顺序查找、折半查找、索引表查找、二叉查找树查找等:
- 所谓的顺序查找,即从查找表的第一个元素开始,依次使用待查找的数字和查找表中的每一个元素进行比较,若匹配则视为查找成功。
- 但不论是顺序查找还是折半、索引表等查找算法,它们的查找效率都与查找表的长度紧密相关,查找表的长度越短,查找的速度也就越快。查找的理想做法是不去或很少进行匹配,因此就出现了另一种高速查找的算法,哈希(也称散列)查找。
- 哈希查找算法就是通过一个公式(被称为散列函数)来计算元素的位置,从而尽可能的减少匹配次数。
- HashMap、HashSet等类都是基于哈希算法的,它们之所以可以高速的定位元素的位置,就是因为它们是通过即散列函数来计算出元素的位置的。
散列函数通常是接受一个参数,然后依据这个参数进行计算,并产生一个输出值。如:1
2
3int fun(n){
return 4*n;
}
但是在哈希查找中,不论散列函数设计的多么好,也难免会有冲突出现,也就是说会存在散列函数的输入参数不相同,但是散列函数依据该参数所计算出来的值却是相同的:
这就像 3*4=12 与 2*6=12 是一个道理。
查找的时候会存在冲突,那么存储的时候必然也会存在冲突,解决冲突的方案有多种,笔者就不展开介绍了。
说这些是为了告诉大家两个事情:
- 第一,HashMap中的元素位置是通过计算得来的。
- 第二,在HashMap中,可以同时存在两个Key不同,但hashCode相同的元素。
- 第三,当想把A存入HashMap时,会先使用A的hashCode来计算它将要存储到的位置,若该位置已经有B了,但A和B的key不相同(equals方法返回false),则A会被放到HashMap的其他位置。
回到正题
既然知道了HashMap是通过哈希算法来计算元素的存储位置,那么这意味着元素在HashMap中的排列顺序和插入的顺序可能不同。而当咱们需要遍历HashMap的时候,输出的元素的顺序就不是咱们插入的顺序了。
范例1:输出元素。1
2
3
4
5
6
7
8
9
10
11
12public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Map<String, String> map = new HashMap<String, String>();
map.put("apple", "1");
map.put("orange", "2");
map.put("pear", "3");
System.out.println(map.toString()); // 输出:{orange=2, apple=1, pear=3}
}
}
语句解释:
- 本范例依次将apple、orange和pear加入到HashMap中,但是程序输出的顺序却是orange、apple和pear。
- 正是由于Hash的这种特点会带来很多不便,于是LinkedHashMap便应运而生。
LinkedHashMap
LinkedHashMap是HashMap的子类,它解决了遍历HashMap的无序的问题。
范例1:顺序一致。1
2
3
4
5
6
7
8
9
10
11
12public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
Map<String, String> map = new LinkedHashMap<String, String>();
map.put("apple", "1");
map.put("orange", "2");
map.put("pear", "3");
System.out.println(map.toString()); // 输出:{apple=1, orange=2, pear=3}
}
}
LinkedHashMap内部的链表提供了两种元素的排列方式:
- 按照元素插入的顺序(默认)。
- 按访元素访问的顺序。每当元素被访问(通过get、put等方法)的时候,就将元素移至链表尾部。
范例2:删除元素。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class MainActivity extends ActionBarActivity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// 三个参数依次为:HashMap的初始容量、加载因子、是否启用“按访元素访问的顺序”排序。
Map<String, String> map = new LinkedHashMap<String, String>(0, 0.75f, true) {
protected boolean removeEldestEntry(Entry<String, String> eldest) {
// 若当前已经有4个元素了,则删除eldest。
return size() > 3;
}
};
map.put("1", "100");
map.put("2", "200");
map.put("3", "300");
map.put("4", "400");
map.put("5", "500");
System.out.println(map.toString()); // 输出:{3=300, 4=400, 5=500}
}
}
语句解释:
- 加载因子采用小数表示,0.75表示当Map中的数据量达到总容量的75%时,其容量空间自动扩张。
- 每当往LinkedHashMap中添加数据时,都会导致它的removeEldestEntry方法被调用。该方法用来决定是否将参数eldest从removeEldestEntry中删除。
LruCache
虽然LinkedHashMap已经实现LRU算法,但是它只能在对象的数量上做限制,而不可以在对象的大小上进行限制。
- 如现在需要做一个Bitmap对象的缓存,限制缓存区的大小是15MB。
- 只要所有Bitmap的容量加起来不超过15MB即可,至于Map中保存多少个Bitmap对象则不做限制。
而LruCache类则可以在对象的大小上进行限制。
范例1:两级缓存同时使用。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46public class MemoryCache {
// 一级缓存。
private LruCache<String, Bitmap> mL1Cache = new LruCache<String, Bitmap>(1024 * 300) {
protected int sizeOf(String key, Bitmap value) {
int size = 1;
if (value != null) {
size = value.getRowBytes() * value.getHeight();
}
return size;
}
// 每当LruCache类的put等方法被调用后,LruCache都会检查一下当前容量是否超过的最大容量。
// 若是则entryRemoved()方法将被调用。
protected void entryRemoved(boolean evicted, String key, Bitmap oldValue, Bitmap newValue) {
// 当Bitmap的强引用被删除的时候,将其放入二级缓存中。
mL2Cache.put(key, new SoftReference<Bitmap>(oldValue));
}
};
// 二级缓存。
Map<String, SoftReference<Bitmap>>
mL2Cache = new LinkedHashMap<String, SoftReference<Bitmap>>(0, 0.75f, true) {
protected boolean removeEldestEntry(Map.Entry<String, SoftReference<Bitmap>> eldest) {
// 当软引用的个数超过了5则删除表头元素。
return size() > 5;
}
};
public void put(String key, Bitmap bitmap) {
mL1Cache.put(key, bitmap);
}
public Bitmap get(String key) {
// 从一级缓存中读取数据。
Bitmap bitmap = mL1Cache.get(key);
if (bitmap == null) {
// 从二级缓存中读取数据。
bitmap = mL2Cache.get(key).get();
if (bitmap != null) {
// 再次将数据放入到一级缓存中。
mL1Cache.put(key, bitmap);
}
}
return bitmap;
}
}
语句解释:
- MemoryCache类使用两级缓存来缓存Bitmap对象。
- 其中mL1Cache使用强引用缓存,当mL1Cache空间不足时,会将数据移到mL2Cache中。
- 另外mL2Cache不会阻止系统回收Bitmap对象,只要Bitmap对象在外界有强引用被持有,mL2Cache中的值就不会被回收。
本节参考阅读:
DiskLruCache
DiskLruCache 用于实现存磁盘缓存,它通过将缓存对象写入文件系统从而实现缓存的效果。网上有很多关于DiskLruCache教程,笔者也不打算重复造轮子,本节只给出几个简单范例。
推荐阅读:《Android DiskLruCache缓存完全解析》
范例1:创建DiskLruCache。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
DiskLruCache mDiskLruCache = null;
try {
File cacheDir = getDiskCacheDir(this, "bitmap");
if (!cacheDir.exists()) {
cacheDir.mkdirs();
}
// 第一个参数:表示缓存文件存放的目录。
// 第二个参数:表示应用的版本号,一般设置为1,当版本号发生改变时,DiskLruCache会清空之前的所有缓存。
// 第三个参数:表示单个节点所对应的数据的个数,一般设置为1。
// 第四个参数:表示缓存的总大小,单位是字节,下面设置的是10M。
mDiskLruCache = DiskLruCache.open(cacheDir, 1, 1, 10 * 1024 * 1024);
} catch (IOException e) {
e.printStackTrace();
}
}
// 获取本地缓存目录。
public static File getDiskCacheDir(Context context, String uniqueName) {
String cachePath = null;
// 若SD卡已就绪,或者SD卡不可移除。
if (Environment.MEDIA_MOUNTED.equals(Environment.getExternalStorageState())
|| !Environment.isExternalStorageRemovable()) {
// 缓存路径为:/Android/data/packageName/cache
cachePath = context.getExternalCacheDir().getPath();
} else {
// 缓存路径为:/data/data/packageName/cache
cachePath = context.getCacheDir().getPath();
}
return new File(cachePath, uniqueName);
}
}
语句解释:
- SD卡上的/Android/data/packageName目录是Android推荐的App数据目录,当App被卸载时系统会自动删除该目录。
- 当本地缓存大于指定的大小时,DiskLruCache会清除一些缓存文件,从而保证总大小不大于这个设定值。
- 在缓存目录下会有一个名为journal文件,它是DiskLruCache的日志文件,程序对每张图片的操作记录都存放在这个文件中。
范例2:写入缓存。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29new Thread(new Runnable() {
public void run() {
try {
String imageUrl = "http://img.my.csdn.net/uploads/201309/01/1378037235_7476.jpg";
// 由于图片的url中可能存在特殊字符,所以先将url转成一个MD5字符串,作为唯一标识。
String key = hashKeyForDisk(imageUrl);
// DiskLruCache的缓存添加的操作需要通过Editor完成。
// Editor表示一个缓存对象的编辑对象,如果这个缓存正在被编辑,那么edit方法会返回null。
// 若如果当前本地不存在缓存对象,则edit方法就会返回一个新的Editor对象。
DiskLruCache.Editor editor = mDiskLruCache.edit(key);
if (editor != null) {
// 由于DiskLruCache.open的第三个参数我们设置为1,因此下面的newOutputStream方法传递0。
OutputStream outputStream = editor.newOutputStream(0);
// 执行图片的下载。
if (downloadUrlToStream(imageUrl, outputStream)) {
// 下载成功则提交。
editor.commit();
} else {
// 下载失败则回退。
editor.abort();
}
}
// 将数据写入到本地。
mDiskLruCache.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
语句解释:
- 关于hashKeyForDisk和downloadUrlToStream的具体代码,请参阅上面给出的博文。
范例3:读取缓存。1
2
3
4
5
6
7
8
9
10
11
12
13
14try {
String imageUrl = "http://img.my.csdn.net/uploads/201309/01/1378037235_7476.jpg";
// 获取url的MD5串。
String key = hashKeyForDisk(imageUrl);
// Snapshot表示本地缓存文件的一个快照,通过它我们可以获取缓存文件的输入流。
DiskLruCache.Snapshot snapShot = mDiskLruCache.get(key);
if (snapShot != null) {
InputStream is = snapShot.getInputStream(0);
Bitmap bitmap = BitmapFactory.decodeStream(is);
mImage.setImageBitmap(bitmap);
}
} catch (IOException e) {
e.printStackTrace();
}
语句解释:
- 如果图片的尺寸很大,则上面第9行代码,直接将它加载到内存是很危险的。
- 此时就可以结合LruCache一节的知识,加载缩略图并将图片放到MemoryCache中,至此就实现了三级缓存的功能。
图片的处理
本节将详细的讲解一些图片处理相关的知识。
处理Bitmap本身
在Android中使用Bitmap类来表示位图。在前面我们已经介绍了如何加载一个Bitmap到内存中,本节将继续深入讲解Bitmap的其它操作。
范例1:将Bitmap保存到本地。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16private boolean writeBitmap(Bitmap bitmap,String name){
// 获取一个Bitmap对象。
try{
FileOutputStream output = new FileOutputStream(this.getFilesDir()+"/"+name);
// 将当前Bitmap对象写入到指定的输出流中。若写入成功则返回true 。
if(bitmap.compress(CompressFormat.JPEG, 100, output)){
System.out.println("OK");;
// 释放与当前Bitmap对象所关联的系统资源。
bitmap.recycle();
return true;
}
}catch(Exception e){
e.printStackTrace();
}
return false;
}
语句解释:
- 关于compress方法的两个参数:
- format:Bitmap对象的压缩格式。常见取值:
- CompressFormat.PNG
- CompressFormat.JPEG
- quality:生成的图片的质量,最高质量为100 。若本方法生成的不会失真的PNG格式的图片,则此参数将不起作用。
- 提示:使用此方法可以将一个Bitmap对象保存到手机中,也可以将一个JPEG格式的图片转换为PNG格式的图片,反之也可以。
- 在使用完毕Bitmap对象后,应该调用recycle方法将其所占据的系统资源回收掉。
范例2:获取View的快照。1
2
3
4
5
6
7
8
9
10public void camera(){
this.linearLayout = (LinearLayout) findViewById(R.id.layout);
// 此方法继承自View类,用来设置当前View的缓存图像功能是否启用。
this.linearLayout.setDrawingCacheEnabled(true);
// 当调用getDrawingCache方法获取当前View的缓存图片时,获取到的图片的背景色默认是透明的,可以使用此方法设置缓存图片的背景色。
this.linearLayout.setDrawingCacheBackgroundColor(Color.BLACK);
// 将View的当前外观,截图,然后以Bitmap的形式返回。 此方法相当于为当前View照相。相片内会包含当前控件和其内部的所有子控件。
// 提示:调用此方法前需要先调用setDrawingCacheEnabled方法,开启缓存图像的功能。
this.writeBitmap(linearLayout.getDrawingCache(), "linear.png")
}
语句解释:
- 本范例中调用的writeBitmap方法是一个用来将Bitmap保存到磁盘上的工具方法。
- getDrawingCache方法不可以在Activity的onCreate方法中调用。因为那时,View并没有被显示到屏幕中。
除了上面的操作外,还可以通过Bitmap类的getPixels方法获取它的像素数据,修改内容后,再通过setPixel方法设置到Bitmap中。
矩阵
在实际开发中,我们可能并不满足于仅仅使用ImageView显示一张图片,可能还会想对图片进行缩放、平移、旋转、倾斜,本节将介绍如何通过android.graphics.Matrix(矩阵)类来实现这四种基本操作。
矩阵就是一个m*n(m行n列)的二维数组,而Matrix类用来描述一个3*3矩阵。
此时你可能会问,Matrix和图片的操作(缩放、旋转、移动、倾斜)有什么关系呢?
主要是为了提高性能。开发者将缩放、旋转、移动、倾斜这四种操作综合在一起设置到矩阵中,然后一次性交给系统,再统一将修改后的Matrix对象作用到ImageView、Bitmap等对象上,以此来提高效率。
在正式介绍如何使用Matrix之前,先介绍几个与矩阵相关的知识点,以减少我们之间的知识断层。
基础知识
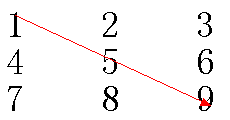
方阵与主对角线
方阵:行数和列数相等的矩阵称为方阵。如 3 x 3、4 x 4 的矩阵都称为方阵。
主对角线:一个 N 阶方阵的主对角线就是方阵从左上到右下的一条斜线。如下图所示:
矩阵加减法
在数学中,矩阵加法一般是指两个矩阵把其相对应元素加在一起的运算。通常的矩阵加法被定义在两个相同大小的矩阵。 如:
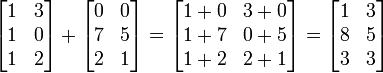
也可以做矩阵的减法,只要其大小相同的话。A-B内的各元素为其相对应元素相减后的值,且此矩阵会和A、B有相同大小。例如:
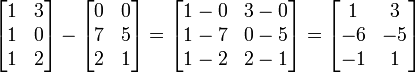
矩阵乘法
矩阵相乘就是指两个矩阵进行乘法运算。矩阵相乘有两个特点:
1、只有当矩阵A的列数与矩阵B的行数相等时A×B才有意义,否则就无法相乘。
2、一个3×2的矩阵乘以一个2×3的矩阵,会得到一个3x3的矩阵。即a(m,n)与b(n,p)相乘结果为c(m,p)。
假设有下面A、B两个矩阵要相乘:1
2
3 1 2 5 6 7
A = 3 4 B = 8 9 10
5 6
具体过程:
- 首先,用A的第一行依次乘以B的每一列。
- C[0][0] = 1*5 + 2*8 也就是用A[0][0]*B[0][0]+A[0][1]*B[1][0]。
- C[0][1] = 1*6 + 2*9 也就是用A[0][0]*B[0][1]+A[0][1]*B[1][1]。
- C[0][2] = 1*7 + 2*10 也就是用A[0][0]*B[0][2]+A[0][1]*B[1][2]。
- 然后,用A的第二行依次乘以B的每一列。
- C[1][0] = 3*5 + 4*8
- C[1][1] = 3*6 + 4*9
- C[1][2] = 3*7 + 4*10
- 最后,用A的第三行依次乘以B的每一列。
- C[2][0] = 5*5 + 6*8
- C[2][1] = 5*6 + 6*9
- C[2][2] = 5*7 + 6*10
矩阵乘法的两个重要性质:
- 矩阵乘法不满足交换律。
- 假设A*B可以相乘,但是交换过来后B*A两个矩阵有可能根本不能相乘。如:A(3,2)*B(2,4)是可以的,但是B(2,4)*A(3,2)就无法相乘。
- 矩阵乘法满足结合律。
- 假设有三个矩阵A、B、C,那么(AB)C和A(BC)的结果的第i行第j列上的数都等于所有A(ik)*B(kl)*C(lj)的和(枚举所有的k和l)。
单位矩阵
在矩阵的乘法中,有一种矩阵起着特殊的作用,如同数的乘法中的1,我们称这种矩阵为单位矩阵。它是个方阵,除主对角线上的元素均为1以外全都为0。 如下图所示:
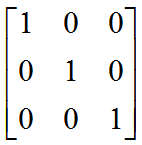
通常用字母E来表示单位矩阵,对于单位矩阵,有A*E=E*A=A。
进入正题
接下来我们开始介绍Matrix类的用法。
前面已经说了,Matrix类支持4种操作:平移(translate)、缩放(rotate)、旋转(scale)、倾斜(skew)。
同时它也是一个3*3的矩阵,由9个float值构成,事实上这9个值目前只使用了前6个,它们各自用来记录不同的数据,如下图:
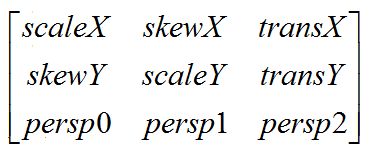
图释:
- 平移位置: 由两个值来记录,即上图中的transX和transY,它表示矩阵当前所在的位置,距离原点的偏移量。
- 缩放大小: 由两个值来记录,即上图中的scaleX和scaleY,表示当前矩阵在水平方向(X轴)和垂直方向(Y轴)上放大的比例。
- 倾斜信息: 由两个值来记录,即上图中的skewX和skewY,表示当前矩阵在水平方向(X轴)和垂直方向(Y轴)上倾斜的大小。
- 旋转角度: 由四个值来记录,即上图中的scaleX和scaleY、skewX和skewY,即通过缩放+倾斜,我们可以实现旋转效果。
提示:一个刚创建的Matrix对象其实就是一个单位矩阵。
值得注意的是,针对每种操作,Matrix类各自提供了pre、set和post三种操作方式。其中:
- set: 用于覆盖Matrix中的值。
- pre: 参与运算的两个矩阵,当前矩阵做为第一个操作数,即在参数矩阵之前。
- post: 参与运算的两个矩阵,当前矩阵做为第二个操作数,即在参数矩阵之后。
因为矩阵的乘法不满足交换律,因此先乘、后乘必须要严格区分,但是矩阵的加法则是满足交换律的。
范例1:平移操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
ImageView img = (ImageView) findViewById(R.id.img);
// 创建一个新的矩阵对象,其实就是创建一个单位矩阵。
Matrix m = new Matrix();
// 将图片的左上角移动到ImageView内部的(100,100)点。
m.setTranslate(100, 100);
// 更新ImageView的矩阵。 必须保证ImageView的android:scaleType="matrix",否则即使修改矩阵也没效果。
img.setImageMatrix(m);
}
}
语句解释:
- 在控制台中输出m就会看到,m[0][2]和m[1][2]的值都变成100了。
范例2:缩放操作。1
2
3
4
5
6
7
8
9
10
11
12
13
14public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
ImageView img = (ImageView) findViewById(R.id.img);
// 获取ImageView的矩阵。
Matrix m = img.getImageMatrix();
// 让图像的宽度放大2倍,高度缩小到0.5倍
m.setScale(2, 0.5f);
// 更新ImageView的矩阵。
img.setImageMatrix(m);
}
}
语句解释:
- 在控制台中输出m就会看到,m[0][0]的值变成了2,m[1][1]的值变成了0.5。
范例3:旋转操作。1
2
3
4
5
6
7
8
9
10
11
12public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
ImageView img = (ImageView) findViewById(R.id.img);
Matrix m = img.getImageMatrix();
// 顺时针旋转45度。
m.setRotate(45);
img.setImageMatrix(m);
}
}
语句解释:
- 让图像顺时针旋转45度,如果想逆时针旋转,则可以设为负数。
倾斜
我们这里所说的倾斜,其实更专业的说法是错切变换(skew),在数学上又称为Shear mapping。它是一种比较特殊的线性变换,错切变换的效果就是让所有点的x坐标(或者y坐标)保持不变,而对应的y坐标(或者x坐标)则按比例发生平移。错切变换,属于等面积变换,即一个形状在错切变换的前后,其面积是相等的。
如下图(左)中,各点的y坐标保持不变,但其x坐标则按比例发生了平移,这种情况叫水平错切。
如下图(右)中,各点的x坐标保持不变,但其y坐标则按比例发生了平移,这种情况叫垂直错切。
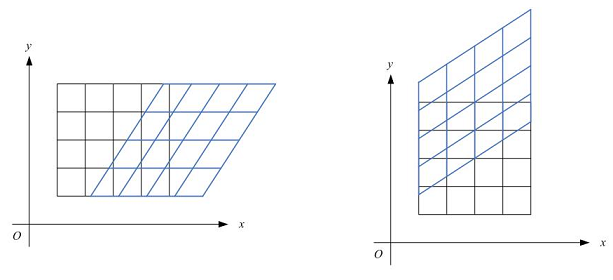
范例1:倾斜操作。1
2
3
4
5
6
7
8
9
10
11
12public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
ImageView img = (ImageView) findViewById(R.id.img);
Matrix m = img.getImageMatrix();
// 让图像的x轴保持不变,y轴倾斜0.4 。
m.setSkew(0, 0.4f);
img.setImageMatrix(m);
}
}
下图(左)是原图,(右)是图片在y轴上倾斜0.4之后的效果,倾斜的数值可以是负数,负数则往逆方向上倾斜。
围绕一个中心点
除平移外,旋转、缩放和倾斜都可以围绕一个中心点来进行,如果不指定,在默认情况下是围绕(0, 0)来进行相应的变换的。 也就是说,setRotate(45)与setRotate(45, 0, 0)是等价的。
范例1:指定旋转的中心点。1
2
3
4
5
6
7
8
9
10
11
12
13
14public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
ImageView imageView = (ImageView) findViewById(R.id.img);
Bitmap bitmap = ((BitmapDrawable)imageView.getDrawable()).getBitmap();
Matrix m = imageView.getImageMatrix();
// 以图片的中心点为原点,顺时针旋转180度。
m.setRotate(180, bitmap.getWidth()/2, bitmap.getHeight()/2);
// 更新ImageView的矩阵。
imageView.setImageMatrix(m);
}
}
语句解释:
- 围绕某一点进行旋转,被分成3个步骤:首先将坐标原点移至该点,然后围绕新的坐标原点进行旋转变换,再然后将坐标原点移回到原先的坐标原点。被围绕的点可以是任意取值,它不受控件大小的限制。比如我们可以围绕(1000, 1000)这个点来旋转。
- 简单的说,可以把用来绘制图像的区域,想象成一个无限大小的画布,当执行旋转时,默认情况下是旋转画布的左上角(0, 0),而若我们指定了一个相对的点,比如(300, 300),那么此时将以画布的(300, 300)为中心了。
前乘与后乘
我们已经知道了,只有当矩阵A的列数与矩阵B的行数相等时A*B才有意义,所以用矩阵A乘以矩阵B,需要考虑是左乘(A*B),还是右乘(B*A)。
左乘:又称前乘,比如说,矩阵A(m,n)左乘矩阵B(n,p),会得到一个m*p的矩阵C(m,p),写作A*B=C。
还有一点值得注意的是,假设A和B都是一个3*3的矩阵,那么A*B与B*A的结果也可能是不一样的。 如下图所示:
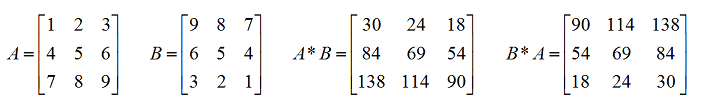
由于矩阵乘法不满足交换律,Matrix类为我们提供了类似的方法,以平移操作为例,Matrix类的源代码为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15/**
* Preconcats the matrix with the specified translation.
* M' = M * T(dx, dy)
*/
public boolean preTranslate(float dx, float dy) {
return native_preTranslate(native_instance, dx, dy);
}
/**
* Postconcats the matrix with the specified translation.
* M' = T(dx, dy) * M
*/
public boolean postTranslate(float dx, float dy) {
return native_postTranslate(native_instance, dx, dy);
}
从注释中可以看出,pre其实执行的就是让当前矩阵左乘参数矩阵,而post则是让当前矩阵右乘参数矩阵。
单次运算
范例1:单次运算——旋转45度。1
2
3
4
5
6
7
8
9
10
11
12
13public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
ImageView img = (ImageView) findViewById(R.id.img);
Matrix m = new Matrix();
// 此处也可以调用postRotate()方法,它们的效果相同。
m.preRotate(45);
img.setImageMatrix(m);
img.setImageBitmap(BitmapFactory.decodeResource(getResources(), R.drawable.ic_launcher));
}
}
语句解释:
- 一个新创建的Matrix对象就是一个单位矩阵。对于平移、缩放、旋转、倾斜四个操作来说,当它们与一个单位矩阵进行运算时,不论调用的是pre还是post方法,最终的效果是一样的。
- 一旦单位矩阵执行了某种操作,那么它就不再是单位矩阵了,此时就需要区分pre和post方法的调用。
范例2:setXxx方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
ImageView img = (ImageView) findViewById(R.id.img);
Matrix m = new Matrix();
m.preRotate(45);
m.preTranslate(100, 100);
m.postSkew(0.2f, 0.2f);
// 不论矩阵之前执行了什么操作,只要它调用了setXxx方法,那么就会先将矩阵重置为单位矩阵,然后再做相应的操作。
m.setScale(2, 2);
img.setImageMatrix(m);
img.setImageBitmap(BitmapFactory.decodeResource(getResources(), R.drawable.ic_launcher));
}
}
语句解释:
- 在本范例中,最终图片只会被放大到2倍,除此之外,其他什么操作都不会执行。
混合连乘
接下来我们通过一个范例来讲解如何进行混合连乘。
范例1:请证明下面两段代码是等价的。1
2
3
4
5
6
7
8
9
10
11
12// 需求是:让图片沿着点(a,b)顺时针旋转30度。
int a = 100, b = 100;
// 第一种实现方式
Matrix m = new Matrix();
m.setRotate(30, a, b);
// 第二种实现方式
Matrix m = new Matrix();
m.setTranslate(a, b);
m.preRotate(30);
m.preTranslate(-a, -b);
第一种实现方式很容易理解,也是不多说,直接说第二种方式。
首先我们得知道,矩阵先乘(preXxx)和后乘(postXX)的区别在于:当前矩阵对象,是先执行参数矩阵的变换,还是后执行参数矩阵的变换。
比如,我们可以根据第二种实现方式写出下面的公式:1
2
3
4// T 表示translate。
// R 表示rotate。
// M1 表示最终的结果矩阵。
M1 = T(a, b) * R(30) * T(-a, -b)
这个公式的推导过程为:1
2
3
4
5
6// 第一步,由于先调用的是m.setTranslate(a, b),所以会先把矩阵重置为单位矩阵,然后再把T放入,得到:
M1 = T(a, b)
// 第二步,由于m.preRotate(30)是前乘,所以直接把参数矩阵放到现有公式的末尾,得到:
M1 = T(a, b) * R(30)
// 第三步,同理,最终得到:
M1 = T(a, b) * R(30) * T(-a, -b)
需要注意的是,在计算的时候,图片会按照从右向左的顺序,依次被每个矩阵变换。
也就是说,公式M1 = T(a, b) * R(30) * T(-a, -b)的语义为:
- 首先,把图片移动到(-a, -b)。
- 然后,让图片以(0, 0)为中心旋转30度。
- 最后,把图片移动到(a, b)。
按照上面的步骤,我们可以直观想一下:
- 第一步,先进行preTranslate(-a, -b)操作,即把原图的左上角平移(-a, -b)个位置,也就相当于把原图的(100, 100)这个位置放到了(0, 0)上。
- 第二步,以(0, 0)为中心旋转30度,就相当于以原图的(100, 100)为中心旋转30度。
- 第三步,旋转完后再平移(a, b),这样原图(100, 100)这个位置的点又回到了它原来的位置。
- 最后,就相当于整个图做了一个以(100, 100)为中心的30度旋转,所以说第一种方式与第二种方式是等价的。
最后,我们再看如果把第二种方式中的m.preRotate(30)变成m.postRotate(30)后,为什么效果就完全不一样了:1
2
3
4
5
6
7// Matrix m = new Matrix();
// m.setTranslate(a, b);
// m.postRotate(30);
// m.preTranslate(-a, -b);
// 最终得到的公式为:
M1 = R(30) * T(a, b) * T(-a, -b)
在上面的公式中,两个平移变换相互抵消了,公式的语义是:以(0,0)为中心旋转30度,这显然和以(100, 100)为中心旋转30度是不同的。
因此,我们可以总结一下:
- m.preTranslate(a, b) :先执行平移(a, b)的变换,再执行matrix中已经定义的其它变换。
- m.postTranslate(a, b) :先执行matrix中已经定义的其它变换,再执行平移(a, b)的变换。
- m.setTranslate(a, b) :清空matrix中所有变换,调用这个函数后,matrix就会只包含平移(a, b)这一个变换。
范例1:移动图片。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26private final class MyOnTouchListener implements OnTouchListener{
private Matrix matrix = new Matrix();
private float preX;
private float preY;
public boolean onTouch(View v, MotionEvent event) {
switch(event.getAction()){
case MotionEvent.ACTION_DOWN:
preX = event.getX(); // 记录用户按下手指时的x坐标。
preY = event.getY(); // 记录用户按下手指时的y坐标。
break;
case MotionEvent.ACTION_MOVE:
float currX = event.getX();// 用户移动手指时,记录当前x坐标。
float currY = event.getY();// 用户移动手指时,记录当前y坐标。
float dx = currX - preX; // 用当前x坐标减去上一次的x坐标。
float dy = currY - preY; // 用当前y坐标减去上一次的y坐标。
// 让matrix在当前位置上,平移dx和dy个位置。
matrix.postTranslate(dx, dy);
preX = currX; // 记录下当前x坐标。
preY = currY; // 记录下当前y坐标。
break;
}
//更新ImageView控件的矩阵。
img.setImageMatrix(matrix);
return true;
}
}
语句解释:
- 把这个类的对象设置到ImageView中即可。
本节参考阅读:
- 百度文库 - Android Matrix基础+详解
- Android中图像变换Matrix的原理、代码验证和应用(一)
- Android中关于矩阵(Matrix)前乘后乘的一些认识
- 百度百科 - 剪切变换
- Android之Matrix用法
- Android学习记录(9)—Android之Matrix的用法
- 云算子 - 在线矩阵相乘计算器
- 百度百科 - 矩阵乘法
颜色矩阵
在实际应用中,我们除了会对图片进行缩放、平移、旋转、倾斜操作外,也会对图片的显示效果做出修改。
比如,我们常见的对图像进行颜色方面的处理有:黑白老照片、泛黄旧照片、低饱和度等效果,这些效果都可以通过使用颜色矩阵(ColorMatrix)来实现。
ColorMatrix
颜色矩阵是一个4*5的矩阵,用来对图片颜色值进行处理。在Android中,颜色矩阵是以一维数组的方式进行存储的(参见ColorMatrix类的源码)。
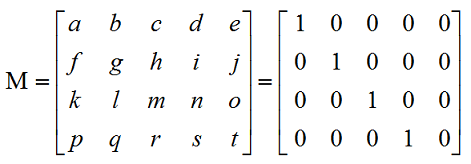
通过颜色矩阵,修改原图像的RGBA值的步骤为:
- 首先,系统会遍历图像中的所有像素点。
- 然后,让每个像素点的颜色值与颜色矩阵进行矩阵乘法运算。
- 接着,将计算出来的新颜色值设置到那个像素点上。
- 最后,当所有像素点都运算完毕后,整张图的颜色就变化完成了。
为了能让像素点的色值和颜色矩阵进行乘法运算,系统会先将像素点的RGBA值存储在一个5*1的分量矩阵中,然后再和颜色矩阵(4*5)相乘。这意味着,我们可以通过修改颜色矩阵的值,来控制图像最终的颜色效果。如下图所示:
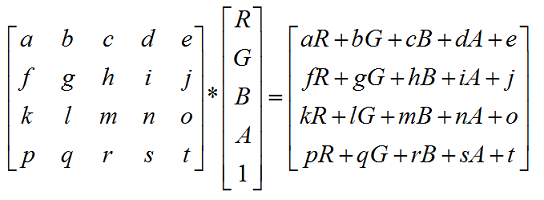
通过阅读ColorMatrix类的源码,得知在上面说的4*5的颜色矩阵中:
- 第一行参数abcde决定了图像的红色成分。即结果矩阵(4*1)的R成分的值=aR+bG+cB+dA+e,如果还不懂那请自行切腹。
- 第二行参数fghij决定了图像的绿色成分。
- 第三行参数klmno决定了图像的蓝色成分。
- 第四行参数pqrst决定了图像的透明度。
并且,从上图可知,颜色矩阵的第五列参数ejot是颜色的偏移量,即如果只是想在像素点现有的颜色上进行微调的话,我们只需要修改ejot即可。
接下来我们通过两个范例来实现下图所示的效果:

范例1:让图片变黄。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
ImageView img = (ImageView) findViewById(R.id.img);
// 创建一个新的颜色矩阵。
ColorMatrix cm = new ColorMatrix();
// 重新设置颜色矩阵中的值。 此处只是将R和G的偏移量设置为100。
cm.set(new float[]{
1, 0, 0, 0, 100,
0, 1, 0, 0, 100,
0, 0, 1, 0, 0,
0, 0, 0, 1, 0,
});
// 创建一个ColorMatrixColorFilter对象,用它来包装一下颜色矩阵,并将它设置到ImageView中。
img.setColorFilter(new ColorMatrixColorFilter(cm));
}
}
语句解释:
- 通过计算后可以得知该颜色矩阵的作用是使图像的红色分量和绿色分量均增加100,这样的效果就使图片泛黄(因为红色与绿色混合后得到黄色)。
范例2:让图片灰度化。1
2
3
4
5
6
7
8
9
10
11
12public class MainActivity extends Activity {
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
ImageView img = (ImageView) findViewById(R.id.img);
ColorMatrix cm = new ColorMatrix();
// 饱和度设置为0 。
cm.setSaturation(0);
img.setColorFilter(new ColorMatrixColorFilter(cm));
}
}
语句解释:
- 饱和度是指色彩的鲜艳程度,也称色彩的纯度,0代表灰,100代表饱和。
- 这样一来,对于被禁用的按钮所显示的图片,如果美工不给,我们也可以自己做出来了。
范例3:修改色调。1
2
3
4
5ImageView imageView = (ImageView) findViewById(R.id.img);
ColorMatrix colorMatrix = new ColorMatrix();
// 系统分别用0、1、2来代表Red、Green、Blue三种颜色,第二个参数表示色调值。
colorMatrix.setRotate(0, 100);
imageView.setColorFilter(new ColorMatrixColorFilter(colorMatrix));
语句解释:
- 色调指的是一幅画中画面色彩的总体倾向,是大的色彩效果。
- 生活中经常见到这样一种现象:不同颜色的物体或被笼罩在一片金色的阳光之中,或被统一在冬季银白色的世界之中。
- 这种在不同颜色的物体上,笼罩着某一种色彩,使不同颜色的物体都带有同一色彩倾向,这样的色彩现象就是色调。
范例4:混合修改。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19ImageView imageView = (ImageView) findViewById(R.id.img);
// 色调
ColorMatrix hueMatrix = new ColorMatrix();
hueMatrix.setRotate(0, 30);
hueMatrix.setRotate(1, 40);
hueMatrix.setRotate(2, 50);
// 饱和度
ColorMatrix saturationMatrix = new ColorMatrix();
saturationMatrix.setSaturation(5);
// 亮度
ColorMatrix lumMatrix = new ColorMatrix();
lumMatrix.setScale(50, 150, 250, 10);
// 将它们三个混在一起。
ColorMatrix matrix = new ColorMatrix();
matrix.postConcat(hueMatrix);
matrix.postConcat(lumMatrix);
matrix.postConcat(saturationMatrix);
imageView.setColorFilter(new ColorMatrixColorFilter(matrix));
本节参考阅读:
第三节 其它
SVG
在Android 5.0(API level 21)中Google提供了对SVG的图片支持。
但需要注意的是,Android是不能直接显示上面创建的原生的SVG文件的,需要在 svg2android 转换一下。
范例1:转换之后的test.xml。1
2
3
4
5
6
7
8
9
10<vector xmlns:android="http://schemas.android.com/apk/res/android"
android:width="48dp"
android:height="48dp"
android:viewportWidth="48"
android:viewportHeight="48">
<path
android:fillColor="#FF0000"
android:pathData="M 0 0 H 48 V 48 H 0 V 0 Z" />
</vector>
语句解释:
- 将这个XML文件放到res/drawable目录都就可以,引用的方法和普通的drawable一样。
- 另外,SVG图片加载到内存时,使用VectorDrawable类来表示。
如果你以为SVG只能绘制很简单的矩形、圆的话,那就错了,比如我们可以用SVG实现下图的效果:

源码地址:
https://github.com/SpikeKing/TestSVG/blob/master/app/src/main/res/drawable/v_homer_simpson_online.xml
注意事项
关于SVG在Android中的应用,还有如下几点要知道:
1、SVG是在5.0中提出的,如果你想在5.0之前使用,则需要导入官方支持库。
2、SVG主要用来降低APK打包大小的,矢量图加载可能会比相应的位图花费CPU运行周期更长,不过在内存使用和性能方面,两者相似。
3、矢量图主要用来制作小的、简单的图片,建议矢量图像最大为200×200dp。
4、Android只支持标准SVG文件的某一些功能,并不是全部,比如不支持gradients和patterns。
上面说到,在Android中SVG和普通位图,在内存使用和性能方面差别不大,有两点可以证明:
1、从VectorDrawable类的draw方法中可以看到,SVG绘制的本质就是解析xml文件,并将里面的各种Path绘制到一个Bitmpa中,然后再将Bitmpa显示。
2、从hprof文件中也可以看到,VectorDrawable最终会持有Bitmap的引用。
在制作SVG时以“mdpi”为标准来设计图片尺寸就可以,这里简单介绍一下各种屏幕密度之间的关系了:
- Google官方推荐,不同屏幕密度的设备,使用的图片尺寸要遵循3(low):4(medium):6(high):8(xhigh):12(xxhigh):16(xxxhigh)。
- 举个例子来说:
- 如果medium下面存放一个48x48尺寸的图片,那么low就应该存放36x36尺寸的图片。
- 相应的就是:high下存放72x72、xhigh下存放96x96、xxhigh下存放144x144、xxxhigh下存放192x192。
- 事实上,Google将存放到medium下面的图片视为基准值,当设备是low密度但是图却是从mdpi中加载的时候,系统就会让图片缩小到原来的75%。
- 对应的比率其实是:low(0.75x)、medium(1.0x)、high(1.5x)、xhigh(2.0x)、xxhigh(3.0x)、xxxhigh(4.0x)。
本节参考阅读:
- 维基百科 - 矢量图
- 维基百科 - 位图
- 百度百科 - 矢量图
- AndroidStudio中使用SVG
- VectorDrawable的工作原理
- Supporting Multiple Screens
- Add Multi-Density Vector Graphics
EXIF
简介
EXIF( Exchangeable image file format,可交换图像文件) 是专门为数码相机的照片设定的,可以记录数码照片的属性信息和拍摄数据。
EXIF最初由小日本电子工业发展协会在1996年制定版本为1.0。1998年升级到2.1,增加了对音频文件的支持。2002年3月发表了2.2版。
EXIF数据可以附加于JPEG、TIFF、RIFF等文件之中,为其增加有关数码相机拍摄信息的内容和索引图或图像处理软件的版本信息。以Windows 7操作系统为例,最简单的查看EXIF信息的方法是右键点击图片打开菜单,点击属性并切换到详细信息标签下即可。
以下列出了几项EXIF会提供的讯息:1
2
3
4
5
6
7
8
9
10
11
12
13
14项目 资讯
制造厂商 Canon
影像方向 正常(upper-left)
影像分辨率Y 300 分辨率单位 dpi
相机型号 Canon EOS-1Ds Mark III
影像分辨率 X 300
Software Adobe Photoshop CS Macintosh
最后异动时间 2005:10:06 12:53:19
YCbCrPositioning 2
闪光灯 关闭
影像拍摄时间 2005:09:25 15:00:18
影像色域空间 sRGB
影像尺寸 X 5616 pixel
影像尺寸 Y 3744 pixel
EXIF信息是可以被任意编辑的,因此只有参考的功能,不能完全相信。
EXIF信息以0xFFE1作为开头标记,后两个字节表示EXIF信息的长度。所以EXIF信息最大为64 kB,而内部采用TIFF格式。
Android支持
从Android 2.0开始新增了ExifInterface类。
此类主要描述多媒体文件比如JPG格式图片的EXIF信息,比如拍照的设备厂商,当时的日期时间,曝光时间等。该类需要调用API Level至少为5即Android 2.0。
范例1:ExifInterface类 。1
2
3
4
5
6
7
8
9
10
11// 获取和设置一个String类型的EXIF信息。 本类还提供了支持设置int、double类型。
public String getAttribute(String tag);
public void setAttribute(String tag, String value);
// 保存标记数据到JPEG文件,此方法很消耗性能。
// 因为它会将当前所有的属性与图片的具体内容组合起来创造一个新图片,然后再删除旧图片,并重命名新图片。
// 因此最好设置完所有属性后,只调用一次本方法,而不是为每个属性都调用。
public void saveAttributes();
// 获取缩略图。
public byte[] getThumbnail();
范例2:常用的Exif信息。1
2
3ExifInterface.TAG_DATETIME // 拍照日期。
ExifInterface.TAG_IMAGE_LENGTH // 图片长度。
ExifInterface.TAG_IMAGE_WIDTH // 图片宽度。
语句解释:
- 若需要其他信息,请自行查阅API文档。
本节参考阅读:
WebP
暂缓。