尽管随着科技的进步,现今移动设备上的内存大小已经达到了低端桌面设备的水平,但是现今开发的应用程序对内存的需求也在同步增长,主要问题出在设备的屏幕尺寸上——分辨率越高需要的内存越多。
熟悉Android平台的开发人员一般都知道垃圾回收器并不能彻底杜绝内存泄露等问题,对于大型应用而言,内存泄露对性能产生的影响是难以估量的,因此开发人员必须要有内存分析的能力。
应用性能优化
虽然本章主要介绍内存优化的知识,但是性能与内存两者息息相关、相互影响,所以下面就先结合Google官方的优化教程以及笔者自己的经验,来说一下应用开发时常见的性能优化手段。
第一节 界面优化
首先是一些常见的界面优化技巧,通过这些技巧可以避免和查找出各类问题,提高程序运行速度。
基础知识
刷新率和帧率
- 屏幕刷新率:代表了屏幕一秒内刷新的次数,60Hz就是屏幕一秒内刷新60次。
- 帧率:代表了GPU在一秒内绘制的帧数,例如60fps就是指GPU一秒钟能生成60张画面,即每秒60帧。
绘制原理
- Android系统要求每一帧都要在16ms内绘制完成,即系统每隔16ms发出VSYNC信号,触发对UI进行渲染,以保持流畅的体验。
- 这样一来系统就可以达到约60帧每秒(1秒/0.016帧每秒 = 62.5帧/秒)的平滑帧率来渲染。
- 如果你的应用没有在16ms内完成这一帧的绘制,假设你花了24ms来绘制这一帧,那么就会出现掉帧的情况。
- 即当系统准备将新的一帧绘制到屏幕上时,但是上一帧并没有画完,所以此时就不会有绘制操作,画面也就不会刷新。反馈到用户身上,就是用户盯着同一张图看了32ms而不是16ms,也就是说掉帧发生了。
为什么是60Fps?
- 由于人类眼睛的特殊生理结构,如果所看画面之帧率高于每秒约10-12帧(即10-12fps)的时候,就会认为是连贯的。
- 电影的拍摄及播放帧率均为每秒24帧,对一般人而言已算可接受,因为这个帧率已经足够支撑大部分电影画面所要表达的内容,同时能最大限度地减少费用支出。不过电影界已经有使用48帧拍摄的电影了 —— 《霍比特人》。
- 但对早期的高动态电子游戏,尤其是射击游戏或竞速游戏来说,帧率少于每秒30帧的话,游戏就会显得不连贯,此时就需要用到60Fps来达到想要表达的效果。
- 因此Android这边也采用了60fps的设计,保持60Fps就意味着每一帧你只有16ms(1秒/60帧率)的时间来处理所有的任务。

垂直同步
- 假设帧率是屏幕刷新率的1/2,那么意味着屏幕刷新2次,GPU才能绘制完一幅画面。
- 相反,如果帧率是刷新率的2倍,那么意味着屏幕刷新1次,GPU能绘制完2幅画面。
- 但是,高于刷新率的帧数都是无效帧数,对画面效果没有任何提升,反而可能导致画面异常。所以许多游戏都有垂直同步选项,打开垂直同步就是强制游戏帧数最大不超过刷新率。
在没有垂直同步的情况下,帧数可以无限高,但屏幕刷新率会受到显示器的硬件限制。
- 所以你可以在60赫兹的显示器上看到200多帧的画面,但是这是200帧的画面流畅程度其实和60帧是一样的,其余140帧全是无效帧数,这140帧的显示信号根本没有被显卡输出到显示器。
- 所以屏幕刷新率的高低决定了有效帧数的多少。
UI绘制机制与栅格化
那么Activity的画面是如何绘制到屏幕上的?那些复杂的XML布局文件又是如何能够被识别并绘制出来的?
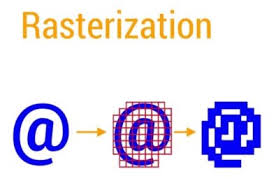
- 绝大多数渲染操作都依赖CPU和GPU两个硬件。
- CPU负责Measure、layout、Record、Execute的计算操作。
- GPU负责栅格化(Rasterization)操作。简单的说,栅格化就是把图像变成像素。
- 比如,将Button、Shape、Path、Bitmap等资源组件拆分到不同的像素上进行显示。这个操作很费时,所以引入了GPU来加快栅格化的操作。
- 显示图片的时候,需要先经过CPU的计算加载到内存中,然后传递给GPU进行渲染。
- 显示文字的时候,需要先经过CPU换算成纹理,然后再交给GPU进行渲染。
- 动画则是一个更加复杂的操作流程,想知道的话,自己查去。
- 因此,非必需的视图组件会带来多余的CPU计算操作,还会占用多余的GPU资源。
主要的原因
通过上面的介绍可以知道,为了能够使得App流畅,我们需要在16ms以内处理完每一帧的CPU与GPU计算,绘制,渲染等操作;否则就会发生掉帧(也就是我们常说的卡顿、不流畅)。
在实际开发中,有如下几种常见情况会导致掉帧。
UI线程任务繁重。
- UI线程是我们的主线程,对于耗时的操作,比如IO操作、网络操作、SQL操作、列表刷新等,应该用后台线程去实现,不能占用主线程。由于界面的绘制也是在UI线程中完成的,因此若UI的任务过多,则就会导致UI延迟绘制、掉帧。
绘制的内容过多。
- 即便我们不让UI线程执行IO、网络等操作,但若界面中需要绘制的内容过多,导致16ms内无法绘制完,也会导致掉帧。
过度绘制严重。
- 和上一条类似,是指在用户看不到的地方上花费了太多的绘制时间(具体后述)。
频繁的触发垃圾回收。
- 垃圾收集的一个潜在的缺点是虚拟机必须追踪运行程序中有用的对象,并释放没用的对象,这一个过程需要花费处理器的时间,进而导致掉帧(具体后述)。
流畅度
我们常说的流畅度低就是指APP卡顿,也就是丢帧。通常影响流畅度有如下几个因素(但不限于):
1、APP的主线程被阻塞,导致主线程没有足够的时间去绘制界面,或者直接导致ANR。
2、APP的界面控件多且复杂,导致主线程虽然不忙但是依然无法在16ms内绘制完一帧。
3、GC频繁,因为GC触发时虚拟机会先暂停所有线程后再执行GC操作,所以当内存泄露、内存抖动等问题发生时,也会导致丢帧发生。
4、操作系统内存不足,当APP向系统申请更多内存时(比如加载大图片),若系统内存不足则系统会执行去杀后台进程等操作回收内存,这就会导致APP阻塞,进而丢帧。
5、CPU饥渴,不论是系统APP还是普通APP,如果其内部开启大量线程执行耗时任务,则就会导致丢帧。道理很简单,同一时间干的事情越多,越容易让主线程得不到CPU去绘制界面。其中SystemServer进程里的各类服务忙碌的话,还会导致AMS等无法为普通APP服务,进而导致普通APP阻塞、丢帧。
本节参考阅读:
过度绘制
过渡绘制是一个术语,表示某些组件在屏幕上的一个像素点的绘制次数超过1次。
通俗来讲,绘制界面可以类比成一个涂鸦客涂鸦墙壁,涂鸦是一件工作量很大的事情,墙面的每个点在涂鸦过程中可能被涂了各种各样的颜色,但最终呈现的颜色却只可能是1种。
这意味着我们花大力气涂鸦过程中那些非最终呈现的颜色对路人是不可见的,是一种对时间、精力和资源的浪费,存在很大的改善空间。绘制界面同理,花了太多的时间去绘制那些堆叠在下面的、用户看不到的东西,这样是在浪费CPU周期和渲染时间!
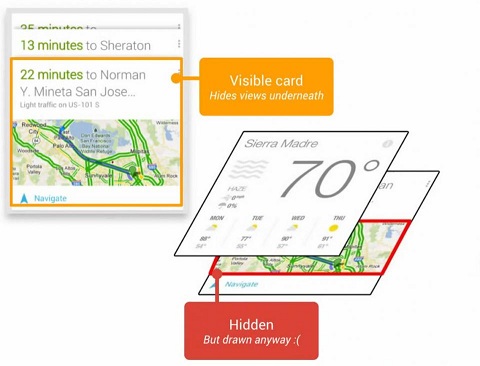
上图中,被用户激活的卡片在最上面,而那些没有激活的卡片在下面,在绘制用户看不到的对象上花费了太多的时间。
追踪过度绘制
通过在手机的开发者选项里打开“调试GPU过度绘制”,来查看应用所有界面及分支界面下的过度绘制情况,方便进行优化。
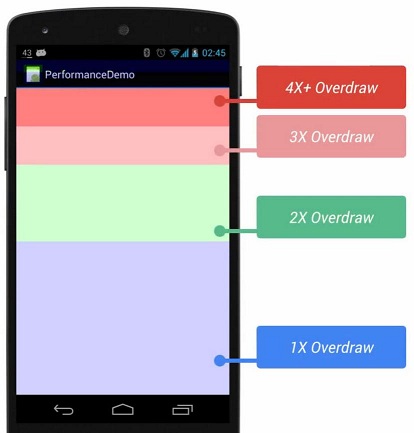
Android会在屏幕上显示不同深浅的颜色来表示过度绘制:
- 没颜色:没有过度绘制,即一个像素点绘制了1次,显示应用本来的颜色;
- 蓝色:1倍过度绘制,即一个像素点绘制了2次;
- 绿色:2倍过度绘制,即一个像素点绘制了3次;
- 浅红色:3倍过度绘制,即一个像素点绘制了4次;
- 深红色:4倍过度绘制及以上,即一个像素点绘制了5次及以上;
设备的硬件性能是有限的,当过度绘制导致应用需要消耗更多资源(超过了可用资源)的时候性能就会降低,表现为卡顿、不流畅、ANR等。
尽管大部分情况下,App 的过度绘制不可避免,但是在开发中,我们还是应该尽可能去减少过度绘制。
实际测试,可以参考以下两点来作为过度绘制的测试指标:
- 应用所有界面以及分支界面均不存在超过4X过度绘制(深红色区域);
- 应用所有界面以及分支界面下,3X过度绘制总面积(浅红色区域)不超过屏幕可视区域的1/4;
过度绘制很大程度上来自于视图相互重叠的问题,其次还有不必要的背景重叠。
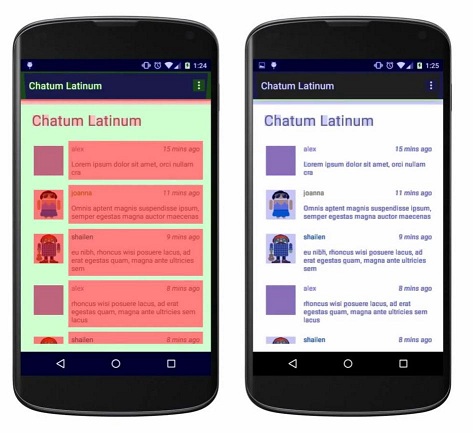
比如一个应用所有的View都有背景的话,就会看起来像第一张图中那样,而在去除这些不必要的背景之后(指的是Window的默认背景、Layout的背景、文字以及图片的可能存在的背景),效果就像第二张图那样,基本没有过度绘制的情况。
自定义控件
在自定义控件的时候也会遇到过度绘制的问题,比如我们连续绘制3遍同样的图片,效果如下图所示:

绘制的代码为:1
2
3
4
5
6
7
8
9
10
11protected void onDraw(Canvas canvas) {
Paint paint = new Paint();
Bitmap bitmap = BitmapFactory.decodeResource(getResources(), R.drawable.img);
int left = 0;
int offsetX = 50;
for (int i = 0; i < 3; i++) {
left = i * offsetX;
canvas.drawBitmap(bitmap, left, 0, paint);
}
}
语句解释:
- 本范例只是为了演示效果,实际开发中不要在onDraw方法中加载Bitmap对象。
- 从效果图里可看出来,在三张图重合的部位,显示出了绿色和红色。
我们可以通过canvas.clipRect()这个方法来设置需要绘制的区域,这个方法用来指定一块矩形区域,只有在这个区域内才会被绘制,在区域之外的绘制指令都不会被执行。

绘制的代码为:1
2
3
4
5
6
7
8
9
10
11
12
13
14protected void onDraw(Canvas canvas) {
Paint paint = new Paint();
Bitmap bitmap = BitmapFactory.decodeResource(getResources(), R.drawable.img);
int left = 0;
int offsetX = 50;
for (int i = 0; i < 3; i++) {
left = i * offsetX;
canvas.save();
canvas.clipRect(left, 0, left + (i == 2 ? bitmap.getWidth() : offsetX), bitmap.getHeight());
canvas.drawBitmap(bitmap, left, 0, paint);
canvas.restore();
}
}
语句解释:
- 简单的说,前两张图片我们只绘制了50的宽度,第三张图片才绘制了完整宽度。
如果你对自定义控件不熟悉,请从《自定义控件篇 第一章 基础入门》 开始阅读。
内存抖动
Android系统里面有一个Generational Heap Memory的模型(具体后述)。
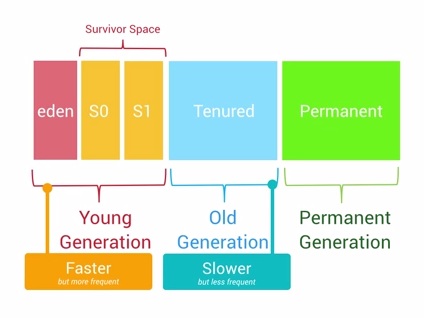
事实上,新创建的对象会先被存放在Young Generation区域,当该对象在这个区域停留的时间达到一定程度,它会被移动到Old Generation,最后到Permanent Generation区域。
- 每一个级别的内存区域都有固定的大小,此后不断有新的对象被分配到此区域,当这些对象总的大小快达到这一级别内存区域的阀值时,会触发GC的操作,以便腾出空间来存放其他新的对象。
- GC所占用的时间和它是哪一个Generation也有关系,Young Generation的每次GC操作时间是最短的,Old Generation其次,Permanent Generation最长。
内存抖动是因为大量的对象被创建又在短时间内马上被释放,如下图所示:
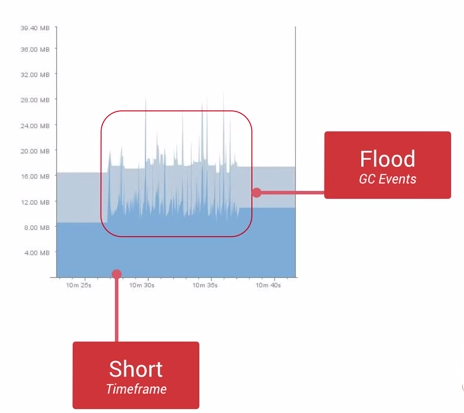
- 瞬间产生大量的对象会严重占用Young Generation的内存区域,当达到阀值剩余空间不够的时候,也会触发GC。
- 即使每次分配的对象占用了很少的内存,但是他们叠加在一起会增加Heap的压力,从而触发更多其他类型的GC。
- 这个操作有可能会影响到帧率(因为GC时会暂停所有线程的执行,包括主线程),并使得用户感知到性能问题。
- 比如二维码扫描的界面就很容易出现内存抖动的问题。
渲染性能
渲染性能往往是掉帧的罪魁祸首,这种问题很常见,让人头疼。好在Android给我们提供了一个强大的工具,帮助我们非常容易追踪性能渲染问题,看到究竟是什么导致你的应用出现卡顿、掉帧。
追踪渲染性能
通过在手机的开发者选项里打开GPU 呈现模式分析,来查看应用所有界面及分支界面下的渲染性能,方便进行优化。
这个工具会在屏幕上实时显示当前界面的最近128帧的GPU绘制图形数据,包括StatusBar、NavBar,以及我们最关心的当前界面的GPU绘制图形柱状图数据。
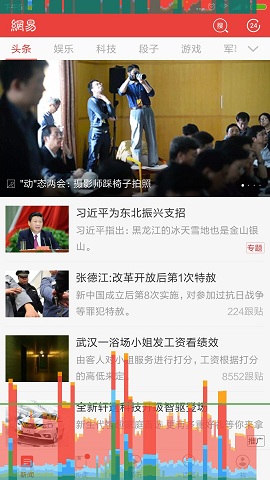
中间有一条绿线,代表16ms,保持动画流畅的关键就在于让这些垂直的柱状条尽可能地保持在绿线下面,任何时候超过绿线,你就有可能丢失一帧的内容。
本节参考阅读:
第二节 代码优化
本节将介绍一些常见的写代码技巧,通过它们可以避免一些内存的消耗,提高程序运行速度。
ArrayMap
在Android开发时,我们使用的大部分都是Java的API(比如使用率非常高HashMap):
- 但是对于Android这种对内存非常敏感的移动平台,很多时候使用一些java的API并不能达到更好的性能,相反反而更消耗内存。
- 所以针对Android这种移动平台,Google也推出了更符合自己的API,比如SparseArray、ArrayMap用来代替HashMap在有些情况下能带来更好的性能提升。
笔者在《媒体篇 第二章 图片》中简单的介绍了HashMap的特点:
- 通过计算元素的hashCode码,实现高速存取元素。
- 内部使用数组+链表来存储元素。
- 元素无序排列。如果你想让集合中元素按照插入的顺序排列可以使用LinkedHashMap类。
下面继续来介绍一下HashMap,并从源码的角度来说明它的一个显著的缺点:浪费内存。
内部原理
开发中,我们常会使用数组和链表来存储数据,但这两者基本上是两个极端。
数组:
- 特点:在内存中开辟连续的存储空间,顺序存储每一个数据元素,相邻的两个元素紧挨着存储。
- 优点:使用下标对元素进行高速的存取。
- 缺点:插入和删除的效率低,因为需要移动元素;尤其在数组的前部进行数据的插入和删除操作。
链表:
- 特点:链表中的结点分散在内存中的各个角落,相邻的结点间通过指针联系。
- 优点:
- 第一,链表中的结点,只有在需要的时候才去建立,不必事先开辟过多空间。
- 第二,删除和增加结点时,不需要移动元素。
- 缺点:链表无法高速存取,当需要查找元素时,只能从表头开始依次遍历,而且每个元素都多出一个指针字段。
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?答案是肯定的,这就是哈希表。
- 哈希表通常由数组和链表组合而成。
- 当存取元素时,会进行如下操作:
- 首先,使用元素来计算出一个值index。
- 然后,将元素存到存到数组的第index位置上去。
- 接着,若数组的index位置上已经有元素了,则会把该元素放到已有元素的后面。
哈希表大体的样子如下图所示:
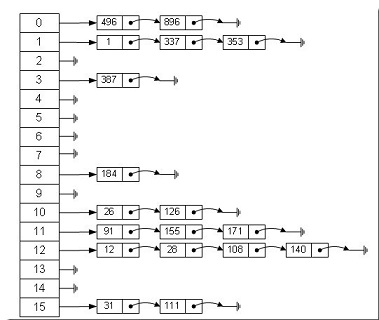
而HashMap就是基于哈希表结构的。
源码阅读
既然上面说HashMap内部使用数组+链表来存储元素,那么数组总有存满的时候,我们来看看它的put方法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31public V put(K key, V value) {
if (key == null) {
return putValueForNullKey(value);
}
// 首先,计算新元素的key的hashCode
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
// 然后,再通过hashCode码计算出,新元素要被放到数组中的哪个位置。
int index = hash & (tab.length - 1);
// 接着,找到tab[index],并依次和这个链表上的每一个元素进行比较。
for (HashMapEntry<K, V> e = tab[index]; e != null; e = e.next) {
// 若找到相同的,则新值覆盖旧值,并返回。
if (e.hash == hash && key.equals(e.key)) {
preModify(e);
V oldValue = e.value;
e.value = value;
return oldValue;
}
}
modCount++;
// 如果当前数组中没有找到与新元素相同的元素,则就把新元素加入到数组中。
// 但在加入之前,先判断数组中当前元素个数是否超过数组长度的75%了,若是,则创建一个2倍于当前数组的新数组。
if (size++ > threshold) {
tab = doubleCapacity();
index = hash & (tab.length - 1);
}
// 把新元素添加到新数组中。
addNewEntry(key, value, hash, index);
return null;
}
语句解释:
- 通过上面的注释可以读明白HashMap的put方法到底做了哪些事。
接下来,我们再来看一下doubleCapacity方法的代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22private HashMapEntry<K, V>[] doubleCapacity() {
HashMapEntry<K, V>[] oldTable = table;
int oldCapacity = oldTable.length;
// 如果数组已经达到最大容量了,则就不创建新数组了。
if (oldCapacity == MAXIMUM_CAPACITY) {
return oldTable;
}
// 否则创建一个2倍大小的新数组。
int newCapacity = oldCapacity * 2;
HashMapEntry<K, V>[] newTable = makeTable(newCapacity);
if (size == 0) {
return newTable;
}
// 将老数组中的元素拷贝到新数组中。
for (int j = 0; j < oldCapacity; j++) {
// ... 此处省略若干代码。
}
return newTable;
}
语句解释:
- 从本范例中可以看出,每当HashMap扩容的时候,都会执行一次复制元素的操作。
问题所在
仔细观察上面的哈希表结构图就会发现一个问题:
- 假设我们有100个元素,在极端的情况下,这100个元素全都被放到数组的第一个元素的链表里了。
- 那么导致的问题就是,数组的其它99个位置是空的。
- 如果元素持续增加的话,就造成了大量的内存浪费,因为元素都集中到某几个链表里了,数组的利用率缺很低。
- 也就是说,数据分布需要均匀(最好数组的每项都只有一个元素),不能太紧也不能太松。
当然,这个问题HashMap肯定考虑到了,但是即便如此也还是存在“数据分布不均匀”的情况。
- 而且从源码上也可以看到,如果HashMap中已经有100个元素了,那么HashMap中的数组可不只100个元素,因为它还需要有预留位置。
- 这意味着HashMap的元素越多,它的空闲状态的预留位置也就可能越多。
这个问题在Java(或则Java服务器端)开发的时候也许不算问题(因为它们不涉及到图片显示,内存主要用来存对象和数据,而且服务端的内存通常都比较大)。但是在Android开发时就不能忍了,所以就有了ArrayMap等类。
ArrayMap的特点
从本质上来说,ArrayMap是牺牲了存取速度,来换取内存的节省。
通过阅读源码可知,ArrayMap使用如下的数组来保存数据:
1 | Object[] mArray; |
语句解释:
- 第n个元素(n>=1)的key保存在mArray[n-1]的位置上。
- 第n个元素(n>=1)的value保存在mArray[n]的位置上。
按照一般的思路,当我们调用arrayMap.get(key)时候,是这样的流程:
- 首先,在ArrayMap中for循环,依次让key和每一个元素的key进行比较。
- 然后,当找到相同的key时,就把key所在位置(n)的下一个(n+1)位置上的元素返回。
这个过程是没有错误的,但是效率太低了,随着数据的增多,遍历的时间也就越久。
为了解决这个问题,ArrayMap中还定义了另一个数组:1
int[] mHashes;
语句解释:
- 它用来保存每一个元素的key的hashCode码。
- 当往ArrayMap中添加数据时,ArrayMap除了会把key/value添加到mArray外,还会把key的hashCode码放到mHashes中。
这样一来,执行get操作的步骤就变为了:
- 首先,ArrayMap会计算出key的hashCode码,我们假设它是x。
- 接着,使用二分查找法从mHashes查找是否存在x,如果存在,则把x的下标记下来,我们假设它是index。
- 最后,ArrayMap直接使用mArray[index<<1]和mArray[index<<1+1]就可以获得元素的key和value了。
- “<<”表示左移,每左移1位数字就变大2倍,而index<<1就表示左移一位。
通过一个mHashes数组,就大幅度提高了查找元素的效率。不过官方对ArrayMap也有说明:
- 它相比传统的HashMap速度要慢。因为查找方法是二分法,并且当你删除或者添加数据时,会对空间重新调整,在使用大量数据时,效率并不明显,低于50%。
- 但是,如果元素能控制在千以内的话,使用ArrayMap完全不需要考虑效率问题。
大家都知道,日常开发时集合里元素低于1000的情况还是比较多的,所以推荐使用ArrayMap。
本节参考阅读:
SparseArray
有时候性能问题也可能是因为那些不起眼的小细节引起的,例如在代码中不经意的“自动装箱”。
我们知道,系统为了能够让基础数据类型正常运作,会做一个autoboxing的操作,比如将int转换成Integer对象。
如下演示了循环操作的时候是否发生autoboxing行为的差异:

Autoboxing的行为还经常发生在类似HashMap这样的容器里面,对HashMap的增删改查操作都会发生。
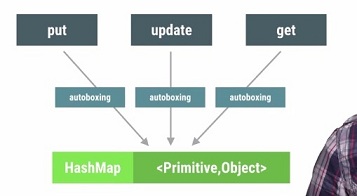
为了避免HashMap的autoboxing行为,系统提供了下面几个容器:
- SparseArray:key是int,value是Object。
- SparseBooleanArray:key是int,value是boolean。
- SparseIntArray:key是int,value是int。
- SparseLongArray:key是int,value是long。
- 这些容器的使用场景也和ArrayMap一致,需要满足数量级在千以内,数据组织形式需要包含Map结构。
Enum
假设我们有这样一份代码,编译之后的dex大小是2556 bytes,在此基础之上,添加一些如下代码,这些代码使用普通static常量相关作为判断值:
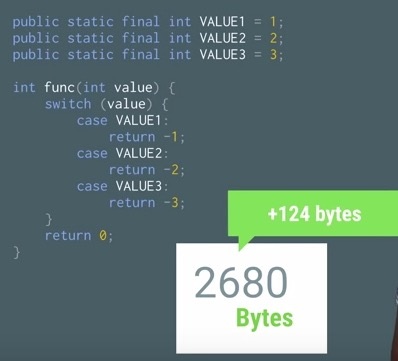
增加上面那段代码之后,编译成dex的大小是2680 bytes,相比起之前的2556 bytes只增加124 bytes。假如换做使用enum,情况如下:

使用enum之后的dex大小是4188 bytes,相比起2556增加了1632 bytes,增长量是使用static int的13倍。不仅仅如此,使用enum,运行时还会产生额外的内存占用,如下图所示:
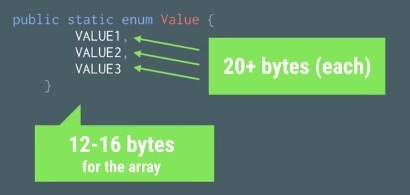
因此,Android官方强烈建议不要在程序里面使用到enum。
ListView
首先,这是一个悲伤的故事:
- 笔者之前在面试的时候,有两次被面试官问到过:“你有哪些ListView优化的方法?”,由于之前没特意优化过ListView,所以只回答出常见的几个方式,因此面试官不太满意。
- 我对此有不同的看法:我更看重的是面试者解决问题的方法和能力,因为“ListView的优化”这个问题,对代码功力要求的不高,反而对知识储备有要求;甚至于学会一种优化的方法可能只需要几分钟的时间而已。
然后,我们收拾一下悲伤的心情,来看看到底有哪些坑爹的优化方法。
最常见的优化方法:
1、使用convertView和ViewHolder类,且ViewHolder应该是静态的(防止持有外部类引用)。
2、延迟加载。即等待滚动条停止的时候再加载,滚动的时候也停止gif动画的播放。
3、异步加载。对于体积比较大的图片等资源,应该在子线程中加载,防止阻塞主线程。
4、防止过度绘制。
5、在getView方法中尽可能少创建对象
最常见的情况,就是为Button设置点击监听器了:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49public class MyListViewAdapter extends BaseAdapter {
private List<String> data;
private View.OnClickListener listener;
public MyListViewAdapter() {
data = new ArrayList<>();
for (int i = 0; i < 100; i++) {
data.add("item"+String.valueOf(i));
}
listener = new View.OnClickListener() {
public void onClick(View v) {
// 获取Item的位置
int position = (Integer) v.getTag();
// 获取是哪个按钮被点击
int btnId = v.getId();
}
};
}
// 此处省略若干方法。
public View getView(int position, View convertView, ViewGroup parent) {
ViewHolder holder = null;
if (convertView == null) {
convertView = LayoutInflater.from(parent.getContext()).inflate(R.layout.item, null);
holder = new ViewHolder();
holder.text = (TextView) convertView.findViewById(R.id.text);
holder.btn1 = (Button) convertView.findViewById(R.id.btn1);
holder.btn2 = (Button) convertView.findViewById(R.id.btn2);
holder.btn1.setOnClickListener(listener);
holder.btn2.setOnClickListener(listener);
convertView.setTag(holder);
} else {
holder = (ViewHolder) convertView.getTag();
}
// 回填数据
holder.text.setText(data.get(position));
// 更新按钮的Tag。
holder.btn1.setTag(position);
holder.btn2.setTag(position);
return convertView;
}
static class ViewHolder {
Button btn1;
Button btn2;
TextView text;
}
}
语句解释:
- 不注意的话,就会有人在getView方法里setOnClickListener(new ...),这样每次getView被调用时,程序都会创建一个监听器对象,这样是很影响效率和内存的。
- 按照上面的写法,整个ListView中所有的Button就共用一个点击事件监听器了。
6、简化每个Iten的布局文件的嵌套层级
推荐阅读:《听FackBook工程师讲Custom ViewGroups》
7、局部刷新
调用notifydatasetchange通知ListView刷新界面会造成getView方法被多次调用,如果是很明确的知道只更新了某一个项的数据,应该尽量避免getView被无辜的多次调用。
解决的方法就是,手动调用getView方法:1
2
3
4
5
6
7
8
9
10
11private void updateSingleRow(ListView listView, long id) {
if (listView != null) {
int start = listView.getFirstVisiblePosition();
for (int i = start, j = listView.getLastVisiblePosition(); i <= j; i++)
if (id == ((Messages) listView.getItemAtPosition(i)).getId()) {
View view = listView.getChildAt(i - start);
getView(i, view, listView);
break;
}
}
}
语句解释:
- 其实可以直接使用recyclerView,它默认就支持局部刷新。
8、采用TextView的预渲染方案
推荐阅读:《TextView预渲染研究》,但该文的作者好像也没把这个优化用到实际项目中。
目前,笔者只找到上面这8个方法,以后如果发现其他方法,那么也会继续更新。
本节参考阅读:
Parcelable和Serializable
我们知道,在开发时不能将对象的引用直接传给目标Activities或者Fragments,而是需要先将它们放到一个Intent或Bundle里面,然后再传递。
我们有两种方式可以将对象放到Intent或Bundle里面,即对对象进行Parcelable或者Serializable化。
作为Java开发者,相信大家对Serializable机制有一定了解,那为什么还需要Parcelable呢?
为了回答这个问题,让我们分别来看看这两者的差异。
范例1:Serializable简单易用。1
2
3
4
5
6
7
8
9public class SeriaPerson implements Serializable {
String name;
int age;
public SeriaPerson(String name, int age) {
this.name = name;
this.age = age;
}
}
语句解释:
- 你只需要对某个类以及它的属性实现Serializable接口即可,无需实现其它任何方法,Java便会对这个对象进行序列化操作。
- 序列化时使用了反射,从而导致序列化的过程较慢;而且在序列化过程中会产生大量的临时对象,从而更加频繁的触发GC。
甚至于直接将一个对象转成JSON格式的字符串,然后保存到本地的效率,都可能比使用Serializable接要高,点击阅读 。
范例2:Parcelable速度至上。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26public class ParcelPerson implements Parcelable {
String name;
int age;
public ParcelPerson(String name, int age) {
this.name = name;
this.age = age;
}
public int describeContents() {
return 0;
}
public void writeToParcel(Parcel dest, int flags) {
dest.writeString(name);
dest.writeInt(age);
}
public static final Parcelable.Creator<ParcelPerson> CREATOR = new Parcelable.Creator<ParcelPerson>() {
public ParcelPerson createFromParcel(Parcel source) {
return new ParcelPerson(source.readString(), source.readInt());
}
public ParcelPerson[] newArray(int size) {
return new ParcelPerson[size];
}
};
}
语句解释:
- 根据google工程师的说法,这些代码将会运行地特别快。原因之一就是我们已经清楚地知道了序列化的过程,而不需要使用反射来推断。
- 不过,很明显实现Parcelable需要写大量的代码,这使得对象代码变得稍微有点难以阅读和维护。
速度测试
当然,我们还是想知道到底Parcelable相对于Serializable要快多少。
范例3:测试代码。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// AActivity.java
public void onClick(View view) {
System.out.println("准备启动:"+System.currentTimeMillis());
Intent intent = new Intent(this, BActivity.class);
for (int i = 0; i < 1000; i++) {
intent.putExtra("person - " + i, new ParcelPerson("person - " + i, i));
}
startActivity(intent);
}
// BActivity.java
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_b);
System.out.println("启动完成:" + System.currentTimeMillis());
}
语句解释:
- 首先,本范例在启动Activity之前,往Intent里面放了1000个对象。
- 然后,在BActivity的onCreate中打印接收到的时间。
- 接着,分别测试使用ParcelPerson和SeriaPerson类时,所消耗的时间。
- 最后,在笔者小米Note手机上测试结果为:
- 使用SeriaPerson类的耗时,大约在200毫秒。
- 使用ParcelPerson类的耗时,大约在100毫秒。
- 需要注意的是,我们写的只是测试代码,实际使用的时候,耗时会随着类的字段数量和结构复杂度的提升而提升。
另外,Parcelable除了效率高外,在IPC等场景下我们只能使用Parcelable类,所以以后就尽量别用Serializable了。
本节参考阅读:
遍历列表
在Java语言中,使用Iterate是一个比较常见的遍历方法。但是在Android中,大家却尽量避免使用Iterator来遍历。
下面我们看下三种不同的遍历方法:1
2
3
4
5
6
7
8
9
10
11
12// for index,即下标遍历
for (int i = 0; i < list.size(); i++) {
}
// for simple
for(String i : list){
}
// Iterator遍历
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
}
使用上面三种方式在同一台手机上,使用相同的数据集做测试,它们的表现性能如下所示:
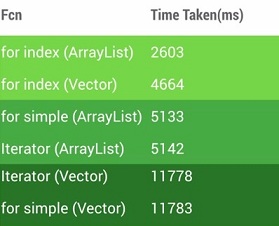
从上面可以看到for index的方式有更好的效率,但是因为不同平台编译器优化各有差异,我们最好还是针对实际的方法做一下简单的测量比较好,拿到数据之后,再选择效率最高的那个方式。
图片处理
调整解码率
常见的png,jpeg,webp等格式的图片在设置到UI上之前需要先载入内存,而载入时可以选择不同的解码格式,不同的格式对内存的占用是有很大差别的。
Android为图片提供了4种解码格式:
- ARGB_8888 每个像素点占32位(即4个字节)
- RGB_565 每个像素点占16位(即2个字节)
- ARGB_4444 每个像素点占16位(即2个字节)
- ALPHA_8 每个像素点占 8位(即1个字节)
另外,低解码格式能节省内存,但清晰度也会有损失,所以需要针对不同场景做不同的处理。
使用inBitmap属性
从Android3.0开始,我们可以在加载位图时为BitmapFactory.Options的Bitmap inBitmap属性设置值。
- 该属性用来告知系统在加载Bitmap时先不要去申请新的内存空间,而是去尝试使用inBitmap所对应的位图的内存区域。
- 利用这种特性,即使是上千张的图片,也只会占用屏幕所能够显示的图片数量的内存大小。
使用inBitmap需要注意几个限制条件:
- 在Api Level 11到18之间,重用的bitmap大小必须是一致的。
- 例如给inBitmap赋值的图片大小为100-100,那么新申请的bitmap必须也为100-100才能够被重用。
- 从Api Level 19开始,新申请的bitmap大小必须小于或者等于已经赋值过的bitmap大小。
- 新申请的bitmap与旧的bitmap必须有相同的解码格式,否则无法重用。例如大家都是8888的。
因此,我们可以创建一个包含多种典型可重用Bitmap的对象池,如下图所示:

Google介绍了一个开源的加载Bitmap的库: Glide ,这里面包含了各种对位图的优化技巧。
第三节 其他优化
优化步骤
大多数开发者在没有发现严重性能问题之前是不会特别花精力去关注性能优化的,通常大家关注的都是功能是否实现。当性能问题真的出现的时候,请不要慌乱。我们通常采用下面三个步骤来解决性能问题。
收集数据
- 我们可以通过Android SDK里面提供的诸多工具来收集CPU,GPU,内存,电量等等性能数据,
分析数据
- 通过上面的步骤,我们获取到了大量的数据,下一步就是分析这些数据。工具帮我们生成了很多可读性强的表格,我们需要事先了解如何查看表格的数据,每一项代表的含义,这样才能够快速定位问题。如果分析数据之后还是没有找到问题,那么就只能不停的重新收集数据,再进行分析,如此循环。
解决问题
- 定位到问题之后,我们需要采取行动来解决问题。解决问题之前一定要先有个计划,评估这个解决方案是否可行,是否能够及时的解决问题。
Lint工具
Lint是Android提供的一个静态扫描应用源码并找出其中的潜在问题的一个强大的工具。
- 例如,如果我们在onDraw方法里面执行了new对象的操作,Lint就会提示我们这里有性能问题,并提出对应的建议方案。
Lint已经集成到Android Studio中了,在“Analyze”菜单中选择“Inspect Code…”,触发之后,Lint会开始工作,并把结果输出到底部的工具栏,我们可以逐个查看原因并根据指示做相应的优化修改。
网络优化
一个网络请求可以简单分为连接服务器和获取数据两个部分;本节将介绍如何在这两个部分上进行优化。
一、连接服务器优化策略
1、不用域名,用IP直连。
- 这样可以省去DNS解析过程,DNS全名Domain Name System,解析意指根据域名得到其对应的IP地址。
- 首次域名解析一般需要几百毫秒,可通过直接向IP而非域名请求,节省掉这部分时间,同时可以预防域名劫持等带来的风险。
- 当然为了安全和扩展考虑,这个IP可能是一个动态更新的IP列表,并在IP不可用情况下通过域名访问。
- 也就是说,服务器端部署了多台机器,有多个IP地址,而客户端将这些IP地址都保存起来,每次请求时选一个地址请求。
2、服务器合理部署。
- 服务器多运营商多地部署,一般至少含三大运营商、南中北三地部署。
- 配合上面说到的动态IP列表,支持优先级,每次根据地域、网络类型等选择最优的服务器IP进行连接。
- 对于服务器端还可以调优服务器的TCP拥塞窗口大小、重传超时时间(RTO)、最大传输单元(MTU)等。
二、获取数据优化策略
1、请求合并。
- 即将多个请求合并为一个进行请求,比较常见的就是一个界面涉及了多类数据,也就会发起多个请求。
2、减小请求数据大小。
- 对于POST请求,Body可以做Gzip压缩。
3、减小返回数据大小。
- 压缩:一般使用Gzip压缩。
- 精简数据格式:如JSON代替XML,WebP代替其他图片格式。
- 对于不同的设备不同网络返回不同的内容,如不同分辨率图片大小。
4、数据缓存。
- 缓存获取到的数据,在一定的有效时间内再次请求可以直接从缓存读取数据。
本节参考阅读:
电量优化
手机各个硬件模块的耗电量是不一样的,有些模块非常耗电,而有些模块则相对显得耗电量小很多。
- 电量消耗的计算与统计是一件麻烦而且矛盾的事情,记录电量消耗本身也是一个费电量的事情。
- 唯一可行的方案是使用第三方监测电量的设备,这样才能够获取到真实的电量消耗。
- 当设备处于待机状态时消耗的电量是极少的,以Nexus 5为例,打开飞行模式,可以待机接近1个月。可是点亮屏幕,硬件各个模块就需要开始工作,这会需要消耗很多电量。
网络请求
网络请求的操作是非常耗电的,其中在移动网络情况下执行网络请求比在WIFI更耗电。
移动网络不同工作强度下,对电量的消耗也是有差异的,消耗有三种状态:
- 全功率:能量最高的状态,移动网络连接被激活,允许设备以最大的传输速率进行操作。
- 低功率:一种中间状态,对电量的消耗差不多是Full power状态下的50%。
- Standby:最低的状态,没有数据连接需要传输,电量消耗最少。
总之,为了减少电量的消耗,在移动网络下,最好做到批量执行网络请求,尽量避免频繁的间隔网络请求(比如消息轮询)。
本节参考阅读:
结尾
相信大家也都知道,性能优化是无止境的,除了上面介绍的通用的优化方法外,我们还可以根据自身App的业务逻辑,来进行进一步的优化。
性能优化相关的知识不是区区一篇博客就能概括的了得,所以笔者以后还会有相关的博文,限于笔者此时能力有限,暂时就先写这么多吧。